| CHWP A.9 | | Tirvengadum, "Linguistic Fingerprints and Literary Fraud" |
1. Introduction
In the mid-nineteen-seventies, France witnessed
one of the most elaborate hoaxes ever to be played on the literary scene
when Romain Gary, a well known French author, published a few novels under
the name of Émile Ajar. The main reason for this subterfuge was
that Gary, already a well-known figure in France (a war hero, a "chevalier
de la légion d'honneur", and a recipient of the Prix Goncourt --
France's highest literary award), wanted to escape from the context in
which critics and readers alike had pegged him, and have his novels judged
on their own merits and not on his established reputation.
His first Ajar novel, Gros-Câlin,
immediately attracted the attention of critics and readers alike and became
a best-seller, while new novels published under the Gary name were not
as successful. When a few astute critics noticed similarities between Gary
and Ajar, Gary vehemently denied having any connection with Ajar. He then
persuaded his nephew, Paul Pavlowich, to impersonate Ajar. To quash any
further rumour that he was Ajar, Gary even accused Ajar of plagiarising
him.
In 1975, with increasing paranoia, Gary
wrote a second Ajar novel, La Vie devant soi, which became an immediate
success; very soon afterwards, Gary/Ajar was awarded the Prix Goncourt.
He thus became the first author (and presumably the last one) to receive
this award twice -- something that is strictly forbidden by the Goncourt
academy.
It was after Romain Gary's suicide in 1980
that two books -- L'Homme que l'on croyait, published in 1981 by
Paul Pavlowich, and the posthumous confession by Gary, Vie et mort d'Émile
Ajar, also published in 1981 -- enabled readers to demystify the double
disguise: Ajar was the pseudonym of Gary and not of Paul Pavlowich. Critics,
then, began to notice similarities between the Gary and the Ajar novels
in terms of ideas, characters, images, recurring motifs and phrasings.
But so far, no one has undertaken a comparative analysis of the Gary and
Ajar literary style using statistical methods.
2. Hypothesis
Nearly all experts of literary style, from
Buffon to Roland Barthes, postulate that style is dictated by the subconscious
and forms the "genetic" fingerprint of a writer's work. This implies, in
the first place, that it is impossible to disguise one's style and, in
the second place, that works written under a pseudonym should contain the
genetic fingerprint of the writer. If Buffon's assertion that "le style
c'est l'homme même" (style makes the writer) is true, the Émile
Ajar corpus should prove to be statistically similar to the Romain Gary
corpus.
The work of Romain Gary provides thus an
excellent example for the study of authorship attribution -- which is,
itself, the analysis of stylistic traits of an author as an index of authenticity.
In this paper we will deal mainly with vocabulary distribution as an element
of style. Firstly, we will look at high frequency words and, secondly,
we will look at synonyms as style discriminants. These two methodologies
are based on the well-known works by John F. Burrows Computation into
Criticism: A Study of Jane Austen's Novels and an Experiment in Method
(Burrows 1987) and a study of style of The
Federalist Papers undertaken by Mosteller and Wallace (Mosteller
and Wallace 1964). Burrows' assertion rests on the premise that the
essential element of an author's style is not confined in the rare lexical
words likely to evoke love, hate or war, but in the forty or fifty unambiguous
and most common word types in the entire corpus. In their analysis of The
Federalist Papers, Mosteller and Wallace focus their research mainly
on the use of synonyms such as while and whilst, on and upon, as
style discriminants to make their conclusions.
3. Methodology
In order to test if the Gary corpus is statistically
similar to the Ajar corpus, I scanned four Gary novels, two of which were
published by Gallimard under the Gary name: Au-delà de cette
limite votre ticket n'est plus valable (Gary 1975a)
and Clair de femme (Gary 1977), and two of
which were published by Le Mercure de France under the Ajar name: Gros-Câlin (Gary 1974) and La Vie devant soi (Gary
1975b). As Romain Gary's literary career spanned nearly thirty years,
these four books, all written within a four year period, were chosen to
avoid problems associated with change in style over time.
After the scanning process, alphabetical
concordances and word counts (using the Oxford Condordance Program [OCP
1989] and WordCruncher [WordCruncher
1988]) were established. From these, another program sorted out the
words in descending order, yielding a list of highest frequency words in
the Ajar and Gary novels. As well, because testing Ajar against Gary would
not in itself have been conclusive, other twentieth-century French novels
were included in the tests: Camus' L'Étranger (Camus
1942), Gide's L'Immoraliste (Gide 1902)
and La Porte étroite (Gide 1904),
and Mauriac's Le Noeud de vipères (Mauriac
1932); for these novels, I consulted a series of texts held in the
ARTFL database (ARTFL 1997).
While it is true that the time-span for
these eight novels ranges from 1902 to 1975, it is safe to assume that
French language, syntax, grammar and usage will not have changed drastically
(if at all) within that time frame. Moreover, these additional four novels
were chosen because they are of similar lengths to the Gary and Ajar books,
they belong to the same genre and, in all of them (as in the Gary and Ajar
novels), the narrator is intradiegetic. A list of high frequency words
compiled by Gunnell Engwall (Engwall 1974) made
up of the most common words in French novels for the period 1962 to 1968
was also included in this study. Most of the work was done on keywords
and not lemmas.
The first part of the research focuses
on the sixty most frequent words in each novel and the Engwall corpus.
Table 1 gives the percentage of
these words in each novel and the Engwall corpus.
The top sixty types constitute between
45.95% and 53.66 % of the entire corpus. (For the identity of these words
and their occurrences per thousand, see the first nine columns of Table
2.) Except for the novel La Vie devant soi, where de occurs
at the relatively low frequency of 23.32 per thousand, de is the
most frequent type in all the other novels and the Engwall corpus. The
most frequent type in La Vie devant soi is et, which ranks
about fourth in the other novels and the Engwall corpus. There are many
other similar examples in Table 2.
To establish if the difference observed in the frequency at which these
words occur is statistically significant, three statistical tests -- Student's
t-test, the Pearson correlation Coefficient, and the Chi-squared
test -- will be employed.
4. Student's t-test
The t-test (which is a variation of
the Standard Normal Curve but is used on small sample sizes) is a method
that will allow us to estimate the mean value of a population, when we
have no information on the standard deviation of that population (in other
words, all French novels having a first person narrator and published in
the twentieth Century) to which all the novels in this study belong.
Table
2 shows the mean value for each type in the 8 novels and the Engwall
corpus under the symbol 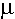 .
(For example the mean value for de is 33.74). The t-test
will also help us determine if the values obtained might merely be expected
to occur by chance alone. For this test, we must choose an alpha level
(or a Confidence Interval), which in this case is the 0.01 (or the 99%
Confidence Interval). This means that all values that fall within two boundaries
established by the 99% Confidence Interval would do so ninety-nine percent
of the time. Any value that falls outside these boundaries would have a
1% likelihood of occurring by chance alone. As we are only dealing with
60 words for each category, this means that very few observations (or only
0.6 observations) should fall outside these boundaries. Table
2 shows these values.
.
(For example the mean value for de is 33.74). The t-test
will also help us determine if the values obtained might merely be expected
to occur by chance alone. For this test, we must choose an alpha level
(or a Confidence Interval), which in this case is the 0.01 (or the 99%
Confidence Interval). This means that all values that fall within two boundaries
established by the 99% Confidence Interval would do so ninety-nine percent
of the time. Any value that falls outside these boundaries would have a
1% likelihood of occurring by chance alone. As we are only dealing with
60 words for each category, this means that very few observations (or only
0.6 observations) should fall outside these boundaries. Table
2 shows these values.
The last two columns in Table
2 show the boundaries within which all values established by the 99%
Confidence Interval would fall. All the novels and the Engwall corpus have
observations falling outside these boundaries. They are as seen in Table
3.
At the 99% Confidence Interval, most of
the novels have between 6.67% and 30% of their observations falling outside
the boundaries, whereas La Vie devant soi has more than 50% of the
observations falling outside the boundaries. This establishes nothing conclusive,
except to show that La Vie devant soi is quite different from the
other novels in this study and has to be investigated further. A statistical
test that is quite useful in this case is the Pearson Correlation Coefficient.
[Return to table of contents] [Continue]