| [CHWP Titles] | |
[CHC 2004] |
mojunker@ccs.carleton.ca |||| http://www.carleton.ca/~mojunker |||| About the Author
radu@monicsoft.net |||| http://www.monicsoft.net/indexr.html |||| About the Author
CHWP A.50, publ. April 2009. © Editors of CHWP 2009.
KEYWORDS / MOTS-CLÉS: Oral stories database, participatory action research, information technology, aboriginal language preservation / Banque de données d'histoires orales, recherche "participaction", technologie de l'information, préservation des langues autochtones.
| section | Introduction: 1. Participatory Action Research for language documentation and preservation |
| 2.0 The web databases | |
| 3.0 Technical Concerns | |
| 3.1 Theoretical and technical approaches following PAR requirements | |
| 3.2 Technical concerns following the presentation medium (Web) | |
| 4.0 Conclusion | |
| References | |
| Notes |
East Cree is a native American language of the Algonquian family,
spoken in
Northern Quebec in the James Bay area. It has 13 000 speakers spread
over 9
different communities and a vast geographical area. There are two
dialects, Northern
East Cree and Southern East Cree, the latter consisting of two
sub-dialects, Inland and
Coastal. In 1995, Cree became the language of instruction from
kindergarten up to
Grade 3 in all Cree schools managed by the Cree School Board, creating
a greater
need for teaching resources for language and culture courses. The
eastcree.org website
was created with the intention to explore how information technology
can assist the
creation and distribution of Cree language resources. A participatory
action research
framework was adopted (Morris &Muzychka, 2002, Junker, 2002), which
meant 1)
that we would focus on the research PROCESS rather than on the research
RESULTS;
2) that the success of our research would depend on the positive impact
it had on
language and speakers; 3) that we would define our goals and methods in
collaboration
with our partners.
A partnership had been established in 2001 with Cree programs, a
department of
the Cree School Board that specializes in creating resources for Cree
language and
culture courses. We work together to ensure the participation and
feedback of
speakers, curriculum designers, and teachers of the language. In the
process, we are
also training willing native speakers in relevant areas like
maintaining the online
databases and editing/archiving digital sound records.
Because the Cree schools are spread over a vast territory, a first
challenge was to
overcome the problem of distance communication. Information Technology
seemed
perfectly suited for this, but few of the existing tools had been
explored or adapted
when we started. Another major challenge is that Cree uses a syllabics
writing system to
which computer technology has been up to now rather unfriendly
(Jancewicz and
Junker, 2002, 2003). With e-mail and chat-rooms becoming increasingly
popular
among native people, but only available in the colonial languages, we
felt that these tools
were one of the many reasons that native languages and culture are
losing ground
relatively fast to western influence. Another goal of our project was
to record and try to
preserve what was left of the memories of the elders and of the Cree
way of thinking
and general world view imprinted on the language with its several
dialects.
The web databases accessible at www.eastcree.org
were developed in order
to systematically organize language material and knowledge in
culturally sensitive ways.
We wanted for example to preserve the oral tradition, a thousand-year
old practice in
Cree culture, and felt that Information Technology could offer a
support previously
unknown. By making old language material available again to the younger
speakers via
the internet, a medium that they love, we felt that there was a greater
chance for
language vitality and survival. The databases had to be accessible to
all concerned, that
is, not only to a few educators, but to all Cree people living in the
Northern
communities, and also to urban, off-reserve natives in need to
reconnect with their
ancestral culture and language. With Cree Programs offices in many
different
communities, hundreds of kilometres apart, the databases had to allow
collaboration at
a distance. They had to allow easy modifications, may it be for
updating the content or
for maintaining the interface and the functionality. Finally a lower
cost compared to
previous ways of doing things (print, paper, postage) was also a
priority.
We started with a publication catalogue, at the request of Cree
Programs staff and
teachers. CP has published hundreds of books for the schools over the
years and
teachers needed a way to know what was available and get it to their
classrooms. We
then worked together on an oral stories database, in order to digitize,
archive and
organize old recordings of elders, recordings which were in danger of
being damaged
by time, and were not accessible. These databases are multi-lingual:
they display four
languages: East Cree Northern, East Cree Southern, French and English.;
two writing
systems (syllabics and roman orthographies) are available. Our more
recent
developments include a Terminology forum and a Cree (syllabics) Chat
room
(www.eastcree.org/ayimuwin)
. Prototypes for
Spelling lessons, Read- and Sing-along
(www.eastcree.org/lessons)
and a Linguistic Atlas ( www.eastcree.org/atlas)
were also developed
using the principles we discuss in this paper. For sake of brevity we
illustrate our
approach primarily with one Database, the oral stories.
The Oral stories Database (www.eastcree.org/stories) is populated with
recordings
from the Cree School Board, academic scholars: anthropologists and
linguists, some
community radio stations, and private (speakers) collections.
At the Cree School Board, there was no systematic centralized archiving
system in
place. The tapes were scattered in several communities, and some had
not been backed
up. Some were already damaged. The original tapes were between 20 and
40 years
old. The same was true of some (speakers' or scholars') private
collections.
There was at the same time an increasing need for educational material
for the upper
grades: children and teens having gone through the Cree as a Language
of Instruction
Program (henceforth CLIP) since 1995, were thirsty for more language
material in
Cree. The focus of Cree Programs had been, like in many other native
communities,
almost exclusively on literacy training (Burnaby, 2004) and there was a
lack of
educational focus on the thousand-year old oral tradition.
The Oral database was thus developed as a response to these needs and
problems.
We wanted a usable tool for collaboration and for storage of results.
And we knew that
our interfaces had to work for users with various (mostly low)
technical expertise levels.
The material had to be organized in culturally-relevant categories, and
that organization
had to be flexible, allowing for online changes without having to
reprogram the database
or the interfaces. For example, the Cree language distinguishes between
stories that are
tipachimuwin, personal stories, memoirs, and stories that are
aatiyuuhkaanh,
archetypal stories, legends and myths. Thus our Cree collaborators
created in the
interface categories that were based on the Cree language, rather than
the English
language. Because we were working primarily with users from the Cree
School Board,
the categorisation had to reflect the potential use by teachers of the
stories, i.e. concerns
with age-appropriateness, curriculum topics, etc. We also had to take
into account the
available hardware, speed of connection and software available in the
Cree schools and
homes.
Figures 1 and 2 are screen shots of the database as it is published on
the web, and
accessible to all users.
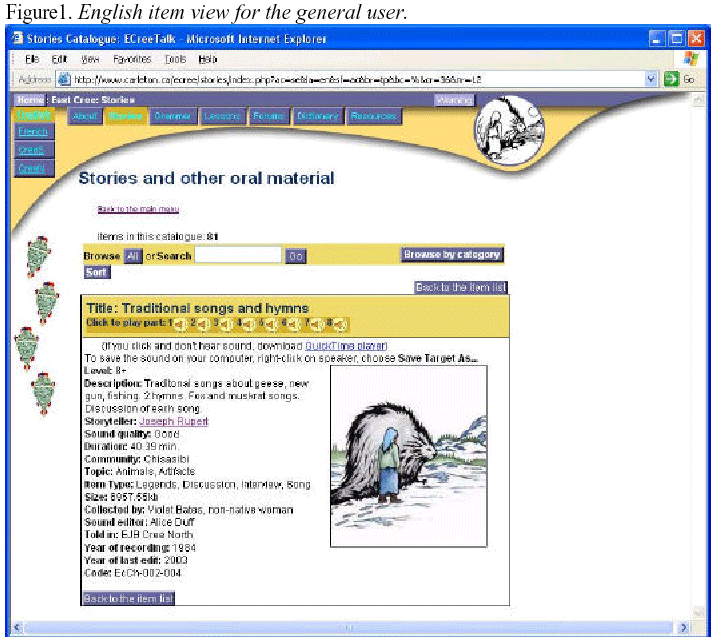
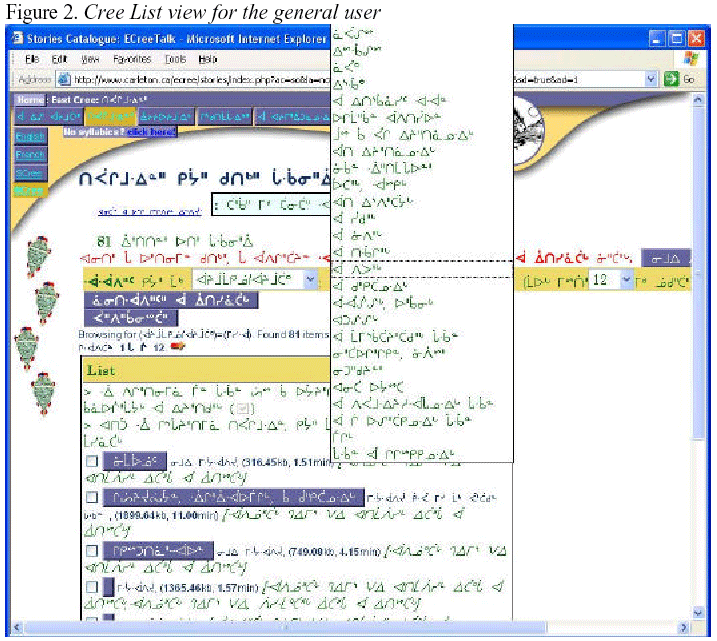
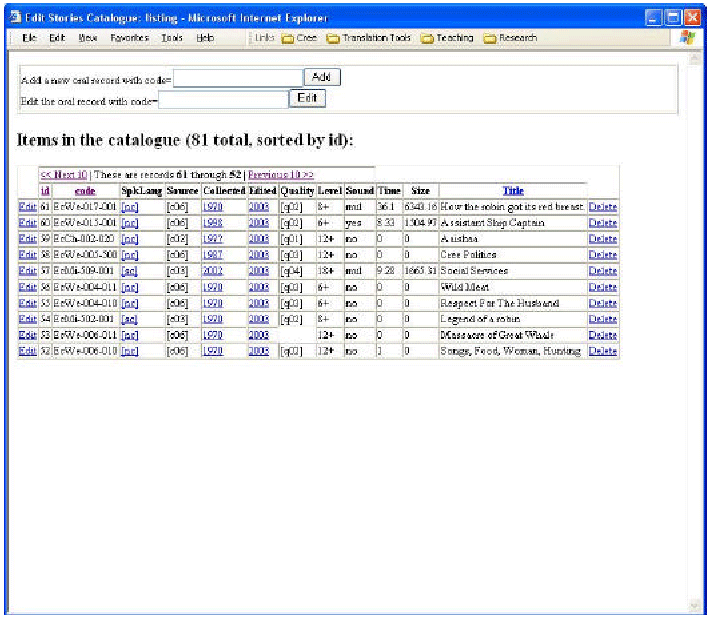
A set of users of the site (employees of Cree Programs), have been
given access to
a separate interface that give them control not only on the content of
the databases, but
also on pieces of layout and even on code elements, as we will detail
in the next section.
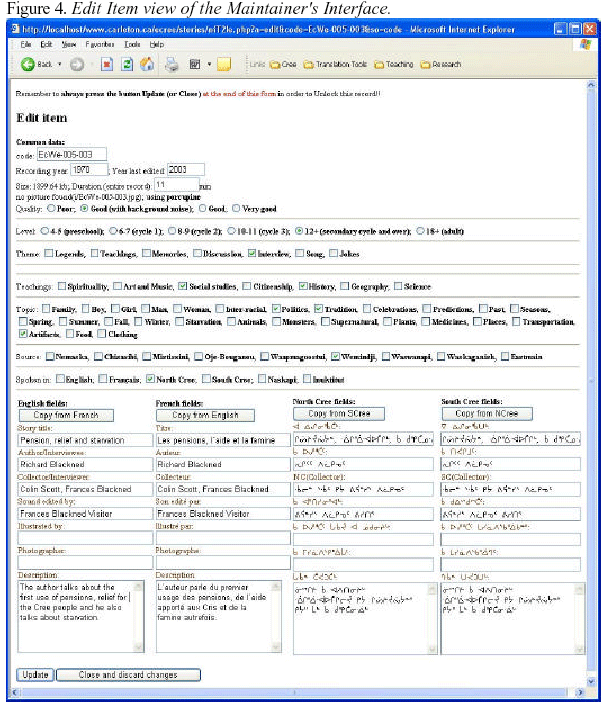
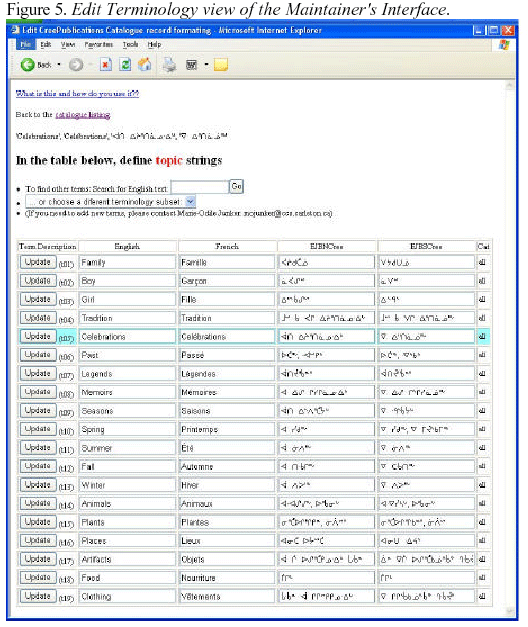
The figures below illustrate these maintainers' interface: for content
control and update,
Figure 3 and 4, and for layout and code Figure 5. For example, the
'Edit Terminology'
window in the maintainers' interface shown in Figure 5 below controls
the 'Topic list'
that appears in the general users' interface shown above in Figure 2.
This is how we
were able to build a user interface in Cree even though the programmer
on the project
does not speak the language.
Now that we presented the task that was ahead of us, and our current solution, let's take a look at how we approached the task and (partially) fulfilled it.
With the requirements set up by our choice of research methodology (Participatory Action Research, henceforth PAR), and by our choice of presentation medium (Web), we had to address many technical concerns in ways that would not detract from the availability of the data. In this section we review these requirements and the solutions we settled on.
We developed the online databases as an application of previous
research
(Luchianov, 2000, 2001) on design patterns. Design patterns in software
engineering
are a reusable methodology for systematically and consistently
developing software (Alexander, 1977). The specific pattern used here
leverages theories from various
branches of Psychology, Software Engineering and Linguistics in order
to set up a
dynamic, active user model which provides recommendations for specific
software
implementation of tools fit for their task and user groups. This
pattern describes
methods like adaptive presentation (generation of documents from pieces
according to
user-specified levels of detail), reduced contextual clutter (present
the most relevant
data possible), context-preserving data mining (access to more data in
a stack of notes
- without having to move to other pages), data access in graph-oriented
rather than
serial paths (as suggested in Spinellis, 2001), transparent
encapsulation of content,
layout and code (allowing for a variety of visibility levels of the
details of implementation
of each element of the application), informative reports (on status and
errors) and active
path markers (buttons with pop-up descriptions rather than text-like
hypertext links) -
to mention a few. A more complete (and evolving) list is available
online at
www.monicsoft.net/proj/mondocp.html.
This research was continued throughout this project. The more useful
aspects of the
design patterns we are working with are that: (1) most of the
components of the
databases (code, templates and multilingual content) are shared; (2)
the site is built
based on a common set of content templates, and it uses a common set of
JavaScript
objects; (3) we continue to modularize, as shared functionality
requires it, while keeping
down to a minimum the number of files to be maintained; (4)
multilingual features are
built right in, for content (e.g. story descriptions), as well as for
the interface layout and
coding. [1]
One of the most important aspects of the design pattern we settled on,
is known in
Software Engineering and Human-Computer Interaction literature as fast
prototyping (REF). Our first attempt at fast prototyping was to
build an online syllabic
communication tool. It evolved into a general transliteration tool for
simultaneous entry
of syllabic and roman orthography, used for example in a Cree chat
room, and in a
terminology forum. As far as the databases are concerned, we started to
work in the
now-classical Object-Oriented paradigm (e.g. White, 1994), spending
lots of resources
on creating development plans, database structures and object models;
we then worked
with the users on first series of prototypes which resulted in the
publication catalogue
(www.eastcree.org/pubcat). This process took more than an academic term
(5-6 months), to
develop and test. For the second database (the oral records
www.eastcree.org/stories), we
used fast prototyping from the start, and due to the design of the
database engine, its
prototype was ready in three days and finalized in an extra couple of
weeks. We reused
modules and built the simplest database structure, functionality and
interface, and grew
from there, as functionality was required by the native users.
Theories like design patterns and fast prototyping have allowed us to
meet most of
the PAR requirements outlined in section 2. Making such flexible
systems available over
large distances, in (relatively cheap) collaboration-friendly
environments becomes then a
more technical matter, which we discuss next.
Until back a decade or so, computer programs used to be mercilessly
optimized in
order to reduce the resources they were using up. However, since the
explosion of
storage and processing power, size and speed optimizations seem to be
relegated to
dreaded computer courses and to the embedded systems where stringent
resource
limitations still exist. We live in a time where bloatware (software
with needlessly huge
install footprint), is no longer a sin, but a common feature. However,
as far as Web
applications are concerned, we still have several limitations (Zhang,
2003): (1)
heterogenic client bases (since people of limited technical background
tend to disregard
upgrading their Web browsers - or not know about the option), (2) low
or inexistent
access to most client machines, a problem common to all Web
applications, and (3)
long transfer times negatively impacting the users' appreciation of the
application and its
data (since we need to supply data to areas where broadband Internet
connectivity has
not reached out fully).
The object-based fast prototyping approach we used (simplifying on
Guerrero,
1998) in developing databases and other aspects of the web site (like
the dynamic
menus), addressed with various degrees of success each of these
limitations. In most of
the current web applications we looked at, the server-mainly
approach had been preferred. [2] Such an approach
gives the developer better control over what clients see
and it reduces the resources necessary for developing and maintaining
the application.
However, it results in very long waiting times, low scalability and
more hardware
resources necessary at the server side, due to the fact that the entire
interface (layouts
and content) has to be built and transmitted to the client each time
the client performs
any action in the application. Since most of our target clients
(CreeSchoolBoard
employees and Cree community computers), are theoretically maintained
by the same
group of people, we chose a balanced client-server approach
that allows us to
decide the amount of work performed at the server-side and to reduce
the amount of
data transferred to the clients.
For example, the database interface is handled by one JavaScript file
(generator)
plus one more for each language supported by the database. These files,
like the rest of
the graphical elements of the interface, are loaded only once per
session (under the
default settings on all web browsers we know of). The language files
are also dynamically generated each time a maintainer changes something
in the parts of the
interface to which the maintainers wanted access (see Figure 5 above).
All the server
sends to the client is a set of properties for the main JavaScript
object (the interface
generator), as for example an array containing the records requested by
the user at any
given time - in a very compact format.
The downside of this approach is that the various platforms and
browsers that are
being used, require special attention. There are differences in the
JavaScript support and
object models implemented in each version of each type of browser, in
the way screen
measurements are done, and in the way multilingual text is supported.
Therefore, the
software that drives the interface has to be designed with these
differences in mind.
Since it's unreasonable to implement each (known) difference from the
start, we
develop for the small range of browsers and platforms that our intended
users have
access to, and from time to time (mostly when we receive bug reports),
we modify the
layout objects to accommodate more of them. Currently, we support
Internet Explorer
5, Netscape 4.7 and Opera 7 on the Windows platforms. Macintosh OSX
systems
which are Unicode-compatible are also supported, but our datbase
interface exhibits
some layout problems since we don't yet have a MacOSX testing machine.
You can see in Figure 2 an example of Cree syllabic text as
part of the oral record
database. The Cree Syllabic character set contains about 136
characters. No operating
system supports this character set natively, but there are several font
sets developed by
researchers, publishers or enthusiasts in various formats, encodings
and typefaces.
Legacy operating systems like Windows 98 and lower, and on MacOS 9.x
and lower
support only 8 bit fonts, which do not allow mixing of syllabic and
roman characters in
the same text field without a lot of overhead in the form of font
formatting tags of some
sort or another. Unicode fonts solve that problem, but: (1) they are
not supported well
on the legacy platforms mentioned above, (2) many of the Web
programming tools
available handle Unicode poorly if at all and (3) the protocols define
lots of encodings,
many of them very verbose (up to a max. of 7 bytes for each character).
Finally, the limitation over which we have most control is long
transfer times. As
we mentioned before, we are separating content and layout. This is done
by using
Cascading Style Sheets and JavaScript objects in modular structures; we
send very little
redundant data from the server. Since the interface is programmed at
the client-side, we
connect to the server less often and the interface is very responsive,
without being
overly crowded. There is a caveat here: hiding functionality behind
buttons which redraw
the interface has proved to be problematic for beginners. So we
resolved to have
two versions of the interface, one for quick searching and browsing the
entire catalogue
(seen in Figure 1), and one with category-based browsing and searching
on specific
fields (seen in Figure 2). An additional one was suggested by the Cree
maintainers
during our last workshop but is not yet implemented; it is very
comprehensive at the
expense of being crowded.
The conditional coding required to render an interface on such a
heterogeneous set
of clients is rather difficult to maintain, especially for
visually-oriented people. Our
choice of client-side support (HTML, JavaScript and CSS), was driven by
the
following facts (1) they generate a flowing, flexible layout, (2) they
have an already large
installed base and (3) there's a relatively very low cost-of-ownership
of the tools
required for development. However, since they require a programmer to
check all
changes, the cost-of-operation of the solution is higher than it was
expected. So we are
looking at an alternative. We have already prepared several prototypes
using
Macromedia Flash (the widely used multimedia editing program which
allows for webembedded
animation, sound and video streaming and lately, client-server
applications).
Versions before Flash MX2004 allowed for pretty difficult data transfer
from the server
and their Unicode support was poor. However, with this new version,
these problems
seem to be fixed and the only deterrents in using this
visually-oriented design and
programming environment are (1) the fixed layout it offers (pages don't
flow like in
HTML, everything happens on a fixed-size 'stage'), (2) learning the
Flash development
style (peculiar for people new to multimedia) of half-visual-design,
half-programming,
(3) the higher price-of-ownership, and (4) the slightly higher
difficulty of packaging
Flash applications (originally designed for copyright protection), as
open source, or
even collaborative projects.
All the measures to reduce the data transferred from the server we
discussed until
now have to do with the interface and the meta-data, the description
of the oral
records.
As far as optimizing the content itself is concerned, anyone who has
used digitized
sound knows the huge amount of storage needed for preserving sound in
lossless
formats. The sound format and sound-editing strategy of the
oral material we chose
resulted from our desire to balance speed, availability and protection
from
appropriation, with the perceived quality of the sound. The mp3 format
was clearly
becoming the most widely used standard for web distribution of sound
files, and since
our project is not commercial, no fees were requires to pay to the
developers of the
technology. After several tests with compressed Windows (wav),
Quicktime (mov),
various codecs for these formats, and the mp3-contender (ogg), we
settled on an mp3
compression format. We judged that this format gives a sufficient
quality for the use
intended, i.e. web listening on the web and private CD burning, while
preventing reappropriation
of the material for commercial use and avoiding the high-pitched
artefacts
of equivalent .ogg compression. In order to reduce the amount of time
spent waiting for
the sound to download, we had to cut our stories into parts. Some oral
records are
more than half an hour long, but we allow the casual listener to get a
short introduction
from which they can gauge the sound quality and make other aesthetic
judgements
about the voice and attitude of the storyteller before having to
download the entire
record. For the same reason, we split files larger than 2Mb in parts,
and so, people with
slow Internet connections can spread the download time over several
sessions without
the use of dedicated downloading software. After consulting our
collaborators about the
acceptable quality loss in the spoken story-like records, we opted for
a sound
compression ratio of 29.4:1 (sound digitized with a sample rate of
44.1kHz and mp3-
streamed at a rate of 24kbps), or 22.1:1 (mp3-streamed at 32kbps) That
compression
plus the 2Mb arbitrary file size limit we set, suggested a maximum of
10 minutes of content for any given parts, or a maximum wait of about
20 seconds per part on a fast
connection (at average latency on a 512kbps DSL), or about 2.5 minutes
on a 56kbps
phone modem. There are issues of usability both for end-users and for
maintainers.
We designed the sound player object in order to make use of whatever
browser
plug-in each computer has installed. The plug-in we are suggesting is
Quick Time or
Windows Media Player, since they appear as part of the interface and
allow the user to
control the sound (start/stop, volume, play-head location, etc.).
However, if the user has
installed some other sound player or sound-editing program that's set
to handle mp3
files, our current solution opens that program as a helper in the
background, with
disconcerting effects (mainly, the database interface loses control
over the playing
sound, thus fails to terminate it when necessary). So we are
considering writing our own
player, in Flash, as we have done for the read-along and sing-along
lessons
(www.eastcree.org/lessons).
To sum up, since we included user feedback in the core of the
development cycle,
we had generally good results at the programming side. The design
pattern used assured
the consistency of the data presentation while adding a level of layout
flexibility almost
impossible with classical database development tools. At the user side,
the interfaces
were very responsive even over 56k modem connections, which resulted in
many
reports of user satisfaction. The design pattern implementation also
allowed the
implementation of additions or modifications almost as they were
suggested by the
users, resulting in increase motivation on their part.
The creation of digital, on-line resources for threatened aboriginal languages presents many technical challenges. These challenges can only be met, if framed in the larger context of a research that also includes educational and ethical challenges. The success in meeting our goal results from always keeping in mind our greater question: "How can information technology help language preservation and documentation and how can the process of creating this resource have a positive impact on the language and its speakers?" The technical approach discussed here is thus framed as an answer to this bigger question. Fast-prototyping, open-source development, proprietary solutions, and database engine design choices were not explored on their own, they came as possible answers to our social and human concerns about the preservation of language and cultural diversity.
Alexander, Christopher, Sara Ishikawa, Murray Silverstein, Max Jacobson, Ingrid Fiksdahl-King, and Shlomo Angel. 1977. A Pattern Language. Oxford: Oxford University Press.
Burnaby, Barbara. 2002. How Have Aboriginal North Americans Responded to Writing Systems in Their Own Languages? Paper given at the Atlantic Provinces Linguistics Association Conference, St. John's, Memorial University.
Guerrero, Luis A., David A. Fuller. 1998. Objects for Fast Prototyping of Collaborative Applications. Proceedings of the 4th CYTED-RITOS International Workshop on Groupware, CRIWG'98, Rio de Janeiro, Brazil, September, 1998.
Jancewicz, Bill and Marie-Odile Junker. 2002. Cree on the Internet: How to Integrate Syllabics with Information Technology and the Web. Presented at the 34th Algonquian Conference, Kingston: Queen's University.
Jancewicz, Bill and Marie-Odile Junker. 2003. Frequently asked questions about Cree syllabics, Computer technology and the Web. In. www.eastcree.org/resources, web pages and PDF download.
Junker, Marie-Odile (ed.) 2000-2004. The East Cree Language Web. www.eastcree.org
Junker, Marie-Odile. 2002. Participatory Action Research in Linguistics: What Does it Mean? / La recherche participaction en linguistique: Enjeux et significations. Presented at the Session on Ethics of Archiving Languages and Fieldwork, organized by the Aboriginal Language Committee, Canadian Linguistics Association Annual Congress, University of Toronto, May 2002.
Luchianov, Mircea-Radu. 2000. MoStaCon: Usability Study for an Experiment Design Tool. Master Thesis. Sofia: New Bulgarian University.
Luchianov, Mircea-Radu. 2001. MonDoc: Effective, personalized active-data documents. Ottawa: Carleton University. Available as a Pdf document at: www.monicsoft.net/proj/msc/COG599.pdf
Morris & Muzychka. 2002. Participatory research and action. Ottawa: Canadian Research Institute on the Advancement of Women.
Spinellis, Diomidis. 2001. Notable design patterns for domain specific languages. Journal of Systems and Software 56(1):91-99.
White, Iseult. 1994. Rational Rose Essentials: Using the Booch Method. Pearson Benjamin Cumming. Redwood City, CA.
Zhang, Jia, C.K. Chang, and J.-Y. Chung. 2003. "Mockup-driven Fast Prototyping Methodology for Web Requirements Engineering", Proceedings of the IEEE 27th Annual International Computer Software and Applications Conference (COMPSAC 2003), Nov. 3-6, 2003, Dallas, TX, USA, pp. 264-269.
1. This approach reduces the task of adding a new
language or dialect to a matter of adding and populating one column in
two of the database tables changing the content of a few rows in other
tables - and of course some relatively minor debugging - all of which
can be done directly online. However, as for most web application
development,
whenever we make major changes to the database we do it safely on a
development
server and we upload changes to the public server only after
preliminary debugging.
2. Dreamweaver and FrontPage templates, Syndeo,
WebCT, Wikis, specialized open source catalogues.