| [CHWP Titles] | |
[CHC 2007] |
yin.liu@usask.ca
|||| About
the Author
jeff@smithicus.com
|||| About
the Author
CHWP A.43, publ. July 2008. © Editors of CHWP 2008.
KEYWORDS / MOTS-CLÉS: relational databases, text encoding, text modelling, markup, XML / base de données relationnelles, encodage des textes, modélisation de texte, étiquetage de textes, XML
| section | 1. Introduction |
| 2. Some difficulties with markup models of text encoding | |
| 3. A relational database model of text encoding | |
| 4. Conclusion | |
| Notes | |
| Works Cited |
There is more than one way to read a text. Consider, briefly, some ways of reading:
(a) Linear reading: that is, reading the text according to a conventional sequence approximating that of speech. This is how we read a narrative or an argument in order to find out what happens next. It is the method of reading privileged by print and therefore most familiar to us. In the terminology of editing theory, this is reading the text or the work, reading the “lexical codes” (Shillingsburg 2006).
(b) Graphical/visual reading: paying attention to the appearance and not just the semantic content of the text and its physical environment -- considering decorations, colour of ink, holes in the manuscript, and the like. A facsimile edition, for example, allows us to accommodate this kind of reading. This has been called reading the document or the artefact, reading the “bibliographic codes” (Shillingsburg 2006).
(c) Analytic reading (or simply analysis): processing the text, often in nonlinear ways, to allow significant patterns to appear. Literary scholars are very familiar with this kind of reading. Take, for instance, a scholarly print edition of a medieval text. The point of a scholarly edition is not only to present a reading text — a student edition does that — but to surround that reading text with editorial apparatus. Thus variant readings are usually provided at the bottom of the page, where more than one manuscript witness exists; or the textual apparatus might provide a history of editorial emendation. The editor’s own explanatory notes are also attached to the reading text, but more often than not troublesomely gathered at the back of the volume. Also at the back of the volume is the glossary, which might be consulted for linguistic reasons but also, if the glossary is very detailed, might serve as a kind of limited concordance to the text. And, not least, it is standard practice to include in the introduction to a scholarly edition of a Middle English text a detailed analysis of the language of the text. Clearly this editorial apparatus necessitates a nonlinear approach to the text; the reader is constantly invited to leave the base text and to glance at the bottom of the page or even flip to the back of the book. Furthermore, the linguistic analysis in the introduction of the edition is the product of hours of tedious scholarly work, running over word-lists, checking rhyme-words — precisely the kind of labour that we wish the computer would do for us.
It is now a truism that the physical presentation of text influences, if not determines, the way we read. It is also worth noting that users tend to approach a new technology with the skills, methods, and presuppositions they learned from old technologies. Thus the codex, with its capacity to support analytic reading — as such tools as a table of contents or an index demonstrate — is still often read like a scroll, cover-to-cover, in linear fashion. The familiarity of this physical platform — what most of us think of when we think of a book — causes us to forget that the codex disassembled and reassembled the scroll in radical ways that made new ways of reading possible. This shift toward enhancing our capacity for analytic reading has been taken further by digital technologies, which have complemented but not replaced our capacity for linear reading (Miall 1998).
Thus it is easy to see why medievalists, for example, were so quick to embrace the new possibilities of computer technologies. The World Wide Web has made it possible for us to read medieval texts on the computer screen and not only in a book. The digital facsimile has brought manuscript studies again to the attention of scholars and students. But in the area of analysis we are still far short of realising the full potential of this technology. To be sure, hypertext editions of medieval material allow us to move from reading-text to editorial apparatus with greater ease than the printed book did — with a quick movement of the mouse rather than a laborious flipping of pages. But we are still very often using the computer for display and dissemination rather than for analysis, and as long as we are doing that, the computer is for us no more than a cumbrous kind of book. This paper proposes a model for text encoding that takes advantage of a powerful and established tool — the relational database — in order to exploit more fully some characteristics of current computer technologies.
The most often invoked model for putting a text into electronic form, at present, is that provided by Extensible Markup Language (XML) especially in the form systematised by the Text Encoding Initiative (TEI). The markup model has its advantages and disadvantages. We do not wish to underplay the tremendous work of the TEI in developing a standard for text encoding projects; and as a means for transforming data from one scheme or database into another, XML is versatile and powerful. But XML is being adopted by many humanities computing projects before consideration of whether it is the best tool for the job. If the intention is exploratory — looking for rather than encoding the structures of the text — then XML begins to show its weaknesses (for an example involving an admittedly difficult medieval text, see Bart 2006).
XML assumes that, to use Allen Renear’s now familiar phrase, a text is an “ordered hierarchy of content objects” (OHCO) (DeRose et al. 1990, but see also Renear et al. 1993). This model has many advantages, but a text is decidedly not neatly hierarchical. Knowledge about a subject is usually very difficult to encapsulate in strictly hierarchical terms without sacrificing its richness and subtlety. Such knowledge often invokes tangential references and linkages between concepts and data scattered throughout the text. In most cases, such encodings are more network-like in their structure than hierarchical. Even if we restrict ourselves to the texts themselves, these are not necessarily hierarchical structures either, and one of the more notorious problems of XML is its awkwardness in encoding structures which are nonhierarchical, which overlap, and which challenge the assumptions of the model itself.
The problem of overlapping hierarchies has been much discussed. One example of an instance in which this problem arises is the situation in which two different ways of reading, for example the linear and the graphical/visual, overlap. A poem in a medieval manuscript, for example, can be encoded as a hierarchy of objects such as stanzas and lines; however, a different way of encoding might mark up the physical divisions of the manuscript itself: quires, leaves, columns. These two hierarchies overlap, and although various solutions to the problem have been suggested, both theoretical and logistical, the existence of overlapping hierarchies remains a challenge.
John Bradley has pointed out that another problem with the OHCO model of text, one that is less frequently discussed but often an issue when encoding medieval materials, is that it does not cope well when we are not reading the text “in document order” (Bradley 2005). As we have already noted, scholars reading analytically very often do not read in linear fashion. Consider also the case of a medieval text that exists in multiple manuscripts and thus in significantly different versions; elements that appear in one order in one witness may appear in a different order in a second witness, or sections may be missing or added in one or the other. The scholar reading analytically--for example, to compare the witnesses for any reason-- may read across the versions, not linearly through each one. What needs to be encoded, therefore, is not only that a group of lines appears as a stanza in one version but also that it corresponds (with significant variation, perhaps) to a group of lines in a different version.
Handling conflicting interpretation of text in XML is also cumbrous. And although very successful collaborative XML projects have been established and are under way, XML does not in itself invite collaborative exploratory work. Having more than one person contributing simultaneously to the same XML document, for example, is a risky business at best.
Furthermore, an XML model commits the “fallacy of prescience,” assuming the structure of the text before one finds out what that structure is (Smith et al. 2006). Right from the start, when writing the DTD, the scholar using an XML approach is forced to define the structure of the text. This is not a problem if one already knows the structure of the text: the tagging then simply makes that structure explicit. But what if the purpose of putting the text into electronic form, amenable to computer analysis, is to find out what the structure is? The scholar in that case will not be able to write a coherent DTD or schema without compromising the aims of the project. In such cases, it is no surprise that the subsequent analysis should find the very structures that were encoded into the schema in the first place.
Another difficulty with XML is that because the markup is in-line, any change to the markup becomes a change to the document as a whole: a complication that standoff markup approaches, such as Just-In-Time Markup (JITM; see Berrie 2000), attempt to resolve. A more versatile system than in-line markup would separate the annotations from the text, even allowing different types or layers of annotations, which could then be applied to the base text as overlays. Bradley has suggested that such an “Object Manipulation Model” might be a better reflection of the way in which scholars work than is the “Markup Model” of XML (Bradley 2005), and has presented further work on annotation tools that support such interaction (Bradley and Vetch 2007).
As a matter of fact, the project that we will be discussing in this paper started off as an XML-encoded text. One of us (Yin Liu) was working on an electronic edition of the 14th-century Middle English poem Sir Perceval of Galles, and chose to encode it in XML-TEI because that was (and still is, to a great extent) the standard practice for projects of this sort. Having done so, we found it very difficult to imagine how to go further — and especially how to perform the kind of paleographical and linguistic analysis for which we tagged the text in the first place. At this point, we shifted to a database model.
Desmond Schmidt, working (significantly enough) on manuscript variants, has suggested that texts themselves, regardless of annotative apparatus surrounding them, may be more usefully modelled as networks (Schmidt 2006). An alternate model might define text, therefore, as “a labelled network of language objects.” A “language object” is like the “content object” in the OHCO model; examples of language objects are chapters, lines, pages, paragraphs, words, symbols. However, a network differs from a hierarchy in allowing more possibilities for connections to be made between the elements of the structure (the “language objects” in this model). The term “labelled” indicates that the meaning of a connection between two elements is attached to the connection itself. Such labelling can be done as the network is being built, and the accumulation of these labels over time indicates what the significant structures might be. This is a more flexible model than the hierarchical, where the relationships between elements are implied by the hierarchical structure, which must be defined before tagging happens. The network model is more useful for exploratory projects because it works in the opposite direction: patterns in the relationships, as they are being labelled, suggest the structures of the text. Furthermore, since connections between language objects can be labelled in different ways, and because the same two elements can participate in more than one connection, each having different labels, this model allows multiple, even conflicting, structures to exist.
Such a definition, it should be noted, does not make any inherent assumptions about the structure of a text — nor, indeed, about the boundaries of a text. The flexibility of this model recognises the complexity of ways in which a text may be defined;1 its rigour comes from the way one chooses to define the relationships that comprise the text. Such a data model already exists and is well established in the computing world: the relational database. Our proposal is not simply to put text (marked up or not) in a database, but to encode text as a database.
This model is a development of an earlier project along the same lines: Callimachus, created by Jeff Smith, Joel Deshaye, and Peter Stoicheff to mark up William Faulkner’s The Sound and the Fury so as to analyse the novel’s complex temporal and narrative structure (Stoicheff et al. 2004). Drawing on his experience with Callimachus, Jeff Smith has created Glyphicus.2 Originally designed as a tool for the transcription of medieval (specifically Middle English) manuscript material, Glyphicus also allows a much broader range of applications. Our test case for this project is the long Middle English poem Sir Perceval of Galles. A database created by Glyphicus includes not only a full and very detailed transcription of the medieval text of Perceval, but also all annotations attached to the text by the project team. Glyphicus provides the medievalist on the team (Yin Liu) with a tool for building a critical edition of the poem, and Perceval provides the computer scientist (Jeff Smith) with an example of a reasonably challenging but not unmanageable text on which to test this model.
When approaching the design of Glyphicus, we sought to model, as best we could, the sorts of practices that have already been used for centuries in the pre-computer world. We sought to amalgamate OHCO documents with network-like, non-hierarchical annotation and markup: underlining, highlighting and marginal notations. Furthermore, in the world of the codex, it is possible for multiple researchers each to have an individual copy of a text, making his or her own marginal annotations in each, or to even share a single copy, creating collaborative marginalia. The physical book truly is a marvel of adaptability to these different modes of working, and we wished not to lose these capabilities in our model. One of the problematic characteristics of the XML-based markup paradigms in use today is that these XML tools tend to introduce cognitive distance between the researcher and the original text. Whereas their training has always put scholars directly in touch with a physical, usually printed copy of the text that they can then read and annotate directly, XML tools introduce a highly opaque view of the text, including embedded tags and tag content interspersed throughout the text. In some situations, an entire computer screen will be filled with nothing but tags and contain no content or scarcely any. This phenomenon might be called “cognitive obfuscation” because such displays interfere with readers’ ability to absorb and observe the very structural relationships that their reading is intended to detect. By contrast, our scheme allows the reader to work directly with a linear version of the text, free from markup, except for those notes and comments that are relevant to the immediate task. In many ways, it is this vision of a readable interface that has driven much of the project design that follows.
Here is a simplified model of the database (see Figures 1 and 2). A word is composed of a sequence of glyphs. These words are stored in a table and are assigned sequence IDs which dictate the order in which the words appear in the document, leaving ample room for subsequent corrections to be inserted into the intervening ranges. “Mapping tables” in the database take care of the sequencing. The document represents the text itself, which is actually just one possible sequence of items from the database. We can therefore add information in the form of annotations to the document. These annotations can be attached to any span of text, from an individual glyph to an entire document.
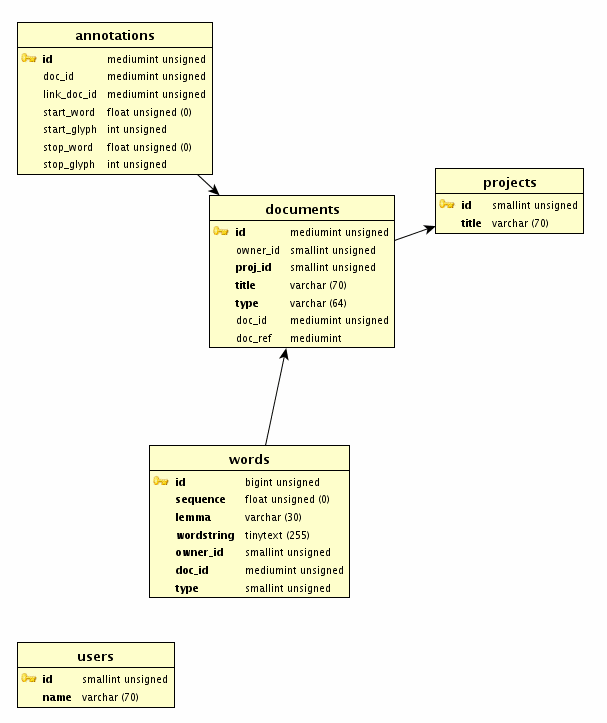
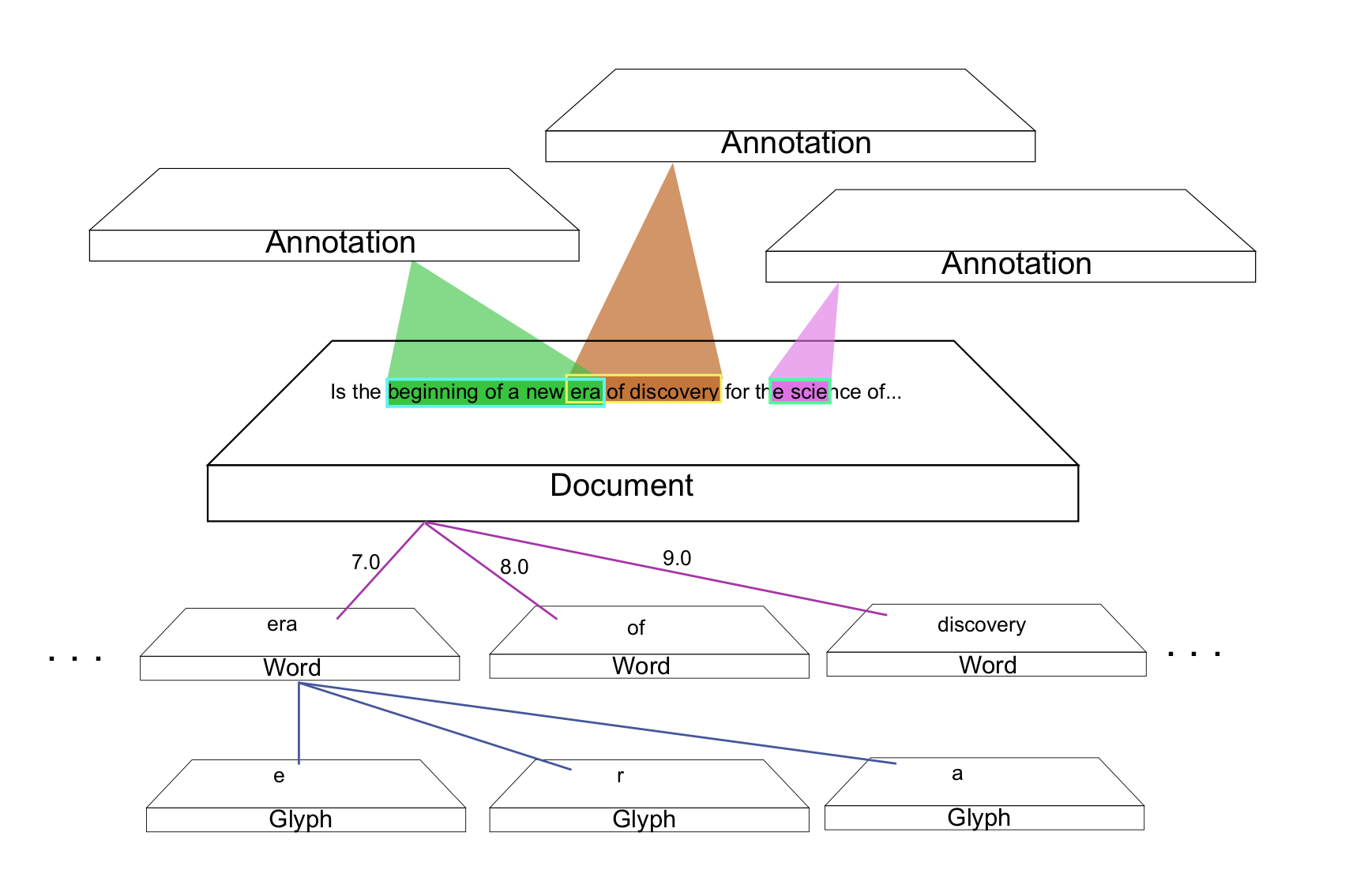
In this project we are dealing with only one manuscript witness for the poem, but this model allows us a very detailed approach to the text: we can analyse the data down to the level of the individual glyphs. The linear rendering of the text (the order in which glyphs appear in the manuscript and the order in which we are intended to read them to find out what happens next) is therefore only one way of extracting the data from the database; it is basically the result of a query that asks for all the glyphs in that sequence.
Glyphicus functions first as a transcription tool. The graphical interface does not require the user to know SQL, but instead allows the user to input and see the text in a familiar way : as text, rather than as text entangled in a mess of tags or dismembered into an array of tables. Inputting text encodes a series of glyphs as a word. These words are sequenced as well, but the flexibility of the relational database structure allows us to move strings of text around easily and at will. Thus, for example, we may find that we have missed a word or even a line, or that what we thought were two words are actually one word with a space in it: the database allows us to make the necessary adjustments with no trouble. In contrast to the XML editor, Glyphicus is designed to hide the technical details of its implementation from the typical user. While our tools are indeed implemented as entries in a set of relational database tables, this structure is never displayed. Instead, it shows up in the interface as different coloured underlines, highlights and “sticky-note,”much like text windows (see Figure 3).
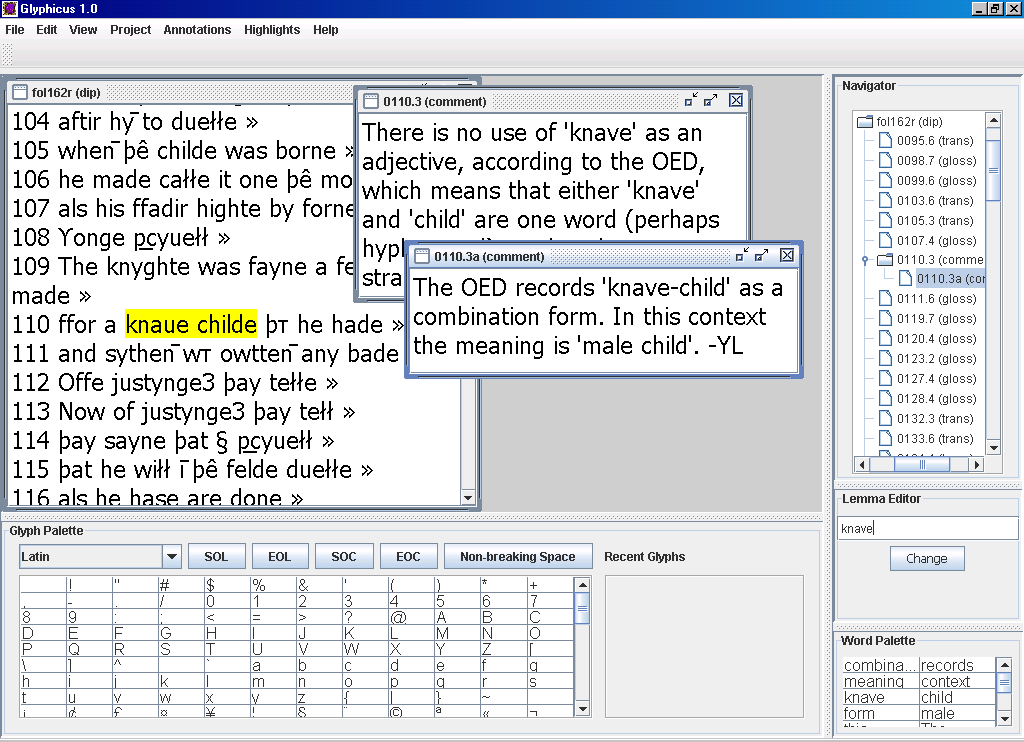
The user interface means that a user (for example, a grad student) working on the text (for example, inputting a transcription or creating annotations) does not first have to be trained in a markup or query language; we can simply give the user a set of transcription protocols, and let him or her worry more about the text than about the encoding. More generally, this model returns the scholarship of texts to a primarily textual interface, rather than immersing it in a thick markup that tends to isolate the researcher from the primary text. Glyphicus also functions as an annotation tool, whereby project team members can build the glossary, add comments, or fight over interpretations. The Perceval project stores the text as a series of documents. At present, we are putting in a paleographical transcription and a diplomatic transcription.3 The transcriptions themselves will contain only what the manuscript shows. Any other information is attached to these base texts as annotations. Annotations can be attached to any span of text, and they can even overlap. We can specify as many different types of annotations as we want and develop as many layers of annotations as we want; in other words, we can annotate annotations. The annotations themselves are part of the database and are in turn available for analysis. They are an example of what Jeff Smith calls “flat tagging,” which is essentially a variant of standoff markup, encoded into relational database form, but with some robust solutions to the nagging “addressing” issues inherent to most XML-based standoff markup systems. Flat tags, as opposed to hierarchically embedded tags such as in XML, can peacefully coexist, even overlap, in a document because the tags do not impart any structure to the content being tagged. This annotation feature is the most significant and powerful advantage of this relational database model.
The database model does indeed encode structure, but it encodes the structure of information, not the structure of the text. The rigour of the result depends not on the constraints of a markup scheme but on the project protocols. For our project, the protocols define the base texts (two kinds of transcription and one reading text),4 the types of annotation allowed, and the ways in which those annotations can be related to the base texts and to each other. For example, annotations pertaining to the physical condition of the manuscript (ink blots, stains, holes, marginalia) are associated with the paleographic transcription. Lemmatisation of the base text, for the purposes of linguistic analysis and for building the glossary, is associated with the diplomatic transcription. Interpretive notes, emendations, and the like are associated with the reading text.
This approach allows the process of creating a scholarly edition to be taken out of the mind of the individual scholar and put into an electronic form that allows others access to and involvement in the process, while at every point acknowledging the importance of the mind of the scholar to the project (the computer can't think for us). At present, the user interface runs as a Java applet. This allows all users to have the latest version of the software, and all users contribute to the same database. The annotation feature allows different users working on the text to contribute different types of information, including interpretations of the text that may conflict. It also allows all of these contributions to remain in the database, so that a user can retrieve, for example, the history of a debate over some textual issue, rather than being provided withonly the interpretation that won. Indeed, this aggregate system of annotation could be a potentially interesting target for meta-analysis: a computer-assisted evaluation of the history of thought on a subject text. Furthermore, this capacity to facilitate collaboration enables a more collaborative model of the literary text, in which (as literary scholars have always known) the text is not a hermetically sealed document but one that interacts with its users and is always implicated in relationships with its sources and influences.
Analysis, in this model, at a basic level, means querying the database. Because the text is the data , it remains open to analysis by tools which have not yet been developed. Analysis does not depend, in other words, on how we tag the text, to the extent that it does with an XML approach. It does depend to some extent on how we set up the database, but we have done so as flexibly and generally as possible, trying to make the fewest assumptions about the structure of the text. Another advantage of the database model is that analysis can be performed while the work is still in progress; we do not have to wait until the tagging is complete before we can query the database. This exploratory analysis, conducted while the work is in progress, is fundamental to our project; for example, decisions about how to resolve glyphs for the diplomatic transcription (questions such as “is that squiggle a decorative flourish or an abbreviation?”) will be based in part on the cumulative results of analysis of the paleographic transcription. We thus enable computer-assisted analysis not just of the end product but at all stages of the project. Doing so makes possible, in the digital environment, one of the fundamental conditions of research, a “hermeneutic of play” (Rockwell 2003).
We have tried to design the Perceval project so that the database is as simple and flexible as possible and the project protocols as rigorous as we wish. Consequently, it is now possible for us to build a number of free-standing analysis tools that can query the database and return results in a variety of forms, such as tables or graphs. For instance, Figure 4 shows the output of a fairly simple tool that graphs glyph sequence frequencies, which can make significant patterns obvious. In this particular case, the graph suggests a shift in scribal practice that warrants further investigation.
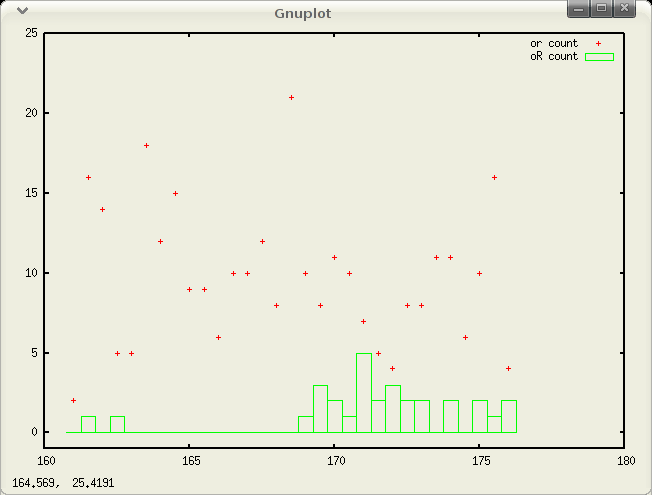
This graph (Figure 4) plots the distribution of the two forms of the grapheme <r> used by the scribe. After the grapheme <o>, the usual form is the “r rotunda” (“round r” or “short r”, here labelled “or"), but, except for a couple of isolated cases near the beginning of the text, the scribe begins to use the “long r” (here labelled “oR”) after <o> at about folio 169r. This anomalous practice does not replace the “r rotunda” after <o>, but it is unusual and coincides with other shifts in scribal practice at the same place in the manuscript.
Because the database is a mature technology, a great many tools exist that permit examination and visualization of their encoded data with relative ease, but it is a mistake to suppose that there exists a suite of such tools that can be brought to bear automatically or instantaneously on a project simply because it is in relational database form. The process of encoding a project into a database indeed renders it highly accessible to these tools for processing, but the tools must still be told about the nature of the encoded relationships and appropriate selections must still be made regarding what aspects of the data to illustrate and in what form.
We are not suggesting that all projects should reject XML out of hand; but, from a technical perspective, the most effective way to encode a large amount of information with a wide variety of internal interconnections and relations is with a relational database. If the purpose of putting the text into electronic form is to prepare it for analysis, this database approach offers a more flexible and, we hope, more powerful alternative to hierarchical markup. For purposes of transferring data from one scheme or database to another, XML is still a useful tool; and it is worth noting that generating XML from a database is possible, and in fact relatively straightforward, as is converting XML data into a relational database. In this sense, embracing a Glyphicus-style encoding strategy is not the same as rejecting XML and TEI. It is perhaps better to think of such relational database encoding as a structural superset of the TEI, from which these other, more static encodings can be easily generated.
A number of thoughtful scholars have suggested ways in which an electronic scholarly edition should take advantage of its differences from print (e.g. Karlsson and Malm 2004, Shillingsburg 2006). We offer here another list, by no means comprehensive, but drawing attention to some advantages of the relational database model that we have presented here:
(a) It should allow nonlinear readings of the text. That is, the text is not only a specific sequence of glyphs, but also an array of data out of which patterns emerge. We might wish, for example, to track variant (dialectical) forms of the word shall in a Middle English text, perhaps displaying them on a graph in order to make their distribution clear. These patterns may not be readily apparent in a linear reading of the text.
(b) It should allow conflicting interpretations of the text. This should include different interpretations of the content of a text: is that character an <o> or an <e>? But it should also allow different views of the structure of a text: whether there is a missing line or lines, whether the poem should be divided into two sections or more. All these interpretations should be equally accessible until (and perhaps even after) some can be demonstrated to be more likely than others.
(c) It should generate discoveries about the text’s system of organisation, not assume them. One purpose of analysis, after all, is to discover structure and pattern. Can spelling variants, for example, confirm a change of scribe in a manuscript, indicate when the same scribe laid aside his work for some time and then resumed it, or perhaps reveal a change of exemplar or change of hand in the exemplar?
(d) Finally, it should be transparent and reproducible; that is, any other scholar should be able to understand the process by which the result was produced and replicate the process to produce the same results. Thus the data on which the analysis was performed should be accessible, and the methods by which the analysis was performed should be readily available as well. The electronic (networked) medium would allow the user not only to have access to the process but also to participate in it, to interact with the project. The electronic environment should be a “work-site” that allows interaction without imperilling the integrity of the data (Eggert 2005; see also Robinson 2005).
The relational database model of text encoding, we hope, fulfills all of these requirements while avoiding some problems of markup-based approaches. It participates in a gradually solidifying sense among people who are interested in computer-assisted text analysis that XML is not the only way of doing things, and that database approaches offer a useful alternative (e.g. Bradley and Short 2005, Ide 2000, Smith et al 2006). It allows exploration and analysis of many different kinds; it also allows the production of an edited text. It puts digital text research directly back in touch with the original document. And finally, it facilitates collaborative work and learning. We hope that this model will open up new ways of defining text and more ways of reading.
1 This is a wide field of discussion and often of controversy in literary and editorial theory; one survey is presented in Greetham 1999.
2 Christopher Cox assisted in implementing Jeff Smith’s design; Kevin Grant provided much of the programming for the user interface; Yan Mao helped with debugging.
3 The paleographic transcription records all variant letter forms; the diplomatic transcription records only those of linguistic significance. Thus two different forms of the character <a> appear in the paleographic transcription but not in the diplomatic.
4 The types of base texts in our project owe a great deal to the idea of “levels of transcription” in the Menota Handbook (Menota 2004); see also Driscoll 2006.
BART, Patricia R. (2006). “Experimental Markup in a TEI-Conformant Setting”, Digital Medievalist 2.1, (URL http://www.digitalmedievalist.org/journal/2.1/bart/).
BERRIE, Phillip William. (2000). “Just in Time Markup for Electronic Editions”, (URL http://www.unsw.adfa.edu.au/ASEC/JITM/Wollongong200004PWB.pdf).
BRADLEY, John. (2005). “What You (Fore)see is What You Get: Thinking About Usage Paradigms for Computer Assisted Text Analysis”, TEXT Technology 14.2: 1-19.
BRADLEY, John, and Harold SHORT. (2005). “Texts into Databases: The Evolving Field of New-style Prosopography”, Literary and Linguistic Computing 20 (Supplementary): 3-24.
BRADLEY, John, and Paul VETCH. (2007). “Supporting Annotation as a Scholarly Tool—Experiences from the Online Chopin Variorum Edition”, Literary and Linguistic Computing 22.2: 225-41.
DeROSE, S. J., D. G. DURAND, E. MYLONAS, and A. H. RENEAR. (1990). “What is Text, Really?”, Journal of Computing in Higher Education 1.2: 3-26.
DRISCOLL, M. J. (2006). “Levels of Transcription” in Electronic Textual Editing (eds. Lou Burnard, Katherine O'Brien O'Keeffe, & John Unsworth), New York: MLA: 254-61.
EGGERT, Paul (2005). “Text-encoding, Theories of the Text, and the \u2018Work-Site\u2019”, Literary and Linguistic Computing 20.4: 425-35.
GREETHAM, D. C. (1999). Theories of the Text, Oxford: Oxford University Press.
IDE, Nancy. (2000). “Searching Annotated Language Resources in XML: A Statement of the Problem”, Athens: ACM SIGIR 2000 Workshop On XML and Information Retrieval, (URL http://www.haifa.il.ibm.com/sigir00-xml/final-papers/Ide/SIGIR-XML.html).
KARLSSON, Lina, and Linda MALM. (2004). “Revolution or Remediation? A Study of Electronic Scholarly Editions on the Web”, HumanIT 7.1: 1-46.
The Menota Handbook: Guidelines for the Electronic Encoding of Medieval Nordic Primary Sources (2004), (gen. ed. Odd Einar Haugen), version 1.1, Bergen: Medieval Nordic Text Archive, (URL www.hit.uib.no/menota/guidelines).
MIALL, David. (1998). “The Hypertextual Moment”, English Studies in Canada 24.2: 157-74.
RENEAR, Allen, Elli MYLONAS, and David DURAND. (1993). “Refining our Notion of What Text Really Is: The Problem of Overlapping Hierarchies”, (URL http://www.stg.brown.edu/resources/stg/monographs/ohco.html).
ROBINSON, Peter. (2005). “Current Issues in Making Digital Editions of Medieval Texts—Or, Do Electronic Scholarly Editions have a Future?”, Digital Medievalist 1.1, (URL http://www.digitalmedievalist.org/journal/1.1/robinson/).
ROCKWELL, Geoffrey. (2003). “What is Text Analysis, Really?”, Literary and Linguistic Computing 18.2: 209-19.
SCHMIDT, Desmond. (2006). “Graphical Editor for Manuscripts”, Literary and Linguistic Computing 21.3: 341-51.
SHILLINGSBURG, Peter L. (2006). From Gutenberg to Google, Cambridge: Cambridge University Press.
SMITH, Jeff, Joel DESHAYE, and Peter STOICHEFF. (2006). “Callimachus—Avoiding the Pitfalls of XML for Collaborative Text Analysis”, Literary and Linguistic Computing 21: 199-218.
STOICHEFF, Peter, et al. (2004). The Sound and the Fury: A Hypertext Edition, University of Saskatchewan, (URL http://www.usask.ca/english/faulkner).