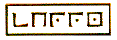
| [CHWP Titles] |
|
[CHC 2007] |
Stan Ruecker,
University of Alberta
|||| http://www.ualberta.ca/~sruecker
||||
About the
Author
Milena
Radzikowska, Mount Royal College
||||
http://www.skrimp.com/mradzikowska/
||||
About
the Author
Piotr Michura, Academy of Fine Arts in Krakow
||||
|||| About
the
Author
Carlos Fiorentino, University of Alberta
|||| http://www.pix.com.ar/carlos
|||| About
the Author
Tanya Clement, University of Maryland
|||| http://www.wam.umd.edu/~tclement/
|||| About
the
Author
CHWP A.46, publ. July 2008. © Editors of CHWP 2008.
KEYWORDS / MOTS-CLÉS: Computer-human interaction, interface design, large screen displays, text mining, data mining, knowledge discovery / Interaction homme-machine, conception d'interface, affichage par grand écran, exploration des données, découverte des connaissances
| section | 1. Introduction |
| 2. Implementing scholarly primitives | |
| 3. Reading for repetition | |
| 4. Text mining for repetition | |
| 5. Interfaces for text mining for repetition | |
| 6. dialR | |
| 7. Repetition graph | |
| 8. Walls of text: the novel as slot machine | |
| 9. Conclusion and future research | |
| Acknowledgements | |
| Works Cited |
This paper discusses a set of research projects in visualizing repeated features of individual documents. These experimental designs have been proceeding as a set of sub-projects by research teams working within the larger Metadata Offer New Knowledge (MONK) project (www.monkproject.org). MONK is an attempt to build on the earlier No One Remembers Acronyms (NORA, at www.noraproject.org) and Wordhoard (http://wordhoard.northwestern.edu/userman/index.html) projects in their efforts to make data-mining and visualization systems available in forms that are congenial to humanities scholars and that work across a wide range of online digital collections.
The visualization component includes both scientific visualizations, where numeric data about the collections are presented in visual forms, and humanities visualization, where text data are presented in visual ways that may or may not include typography. A recurring need in this kind of humanities visualization is to provide information in context, so that the researcher working with a large document (such as a novel, play, or long poem) can have some kind of overview of the entire text, combined with tools for selecting, highlighting, and annotating significant features, without losing the context of the whole. One way that data mining can facilitate this process is in allowing the user to identify a wider range of features than might otherwise be possible using basic functions like a simple string search.
One of our collaborators on MONK, Tanya Clement, is working with the text of a long and complex novel, Gertrude Stein’s Making of Americans (Clement et al., 2007; Clement, 2006). In approximately a thousand pages, or, for the purposes of analysis, 3,174 paragraphs, Stein develops a treatment of her subject that involves recurring references to the same characters through a process of repetition-with-variation. She uses the same words, or variations of the same words, only in different order and in different constructions, and this repetition provokes a sense in the reader of an iterative unfolding of thought.
For instance, the following is one example of many such paragraphs in which phrases are repeated with slight differences:
1Naturally some knew David Hersland had a brother and a sister and a father and a mother. 2 Naturally some were certain that he was in Hersland family living . . . 3He did some things in the way they did things. 4He did some things in the way some of them did some things. 5Some do not like to do things in the way they do things that is in the way some other ones do things. 6Some are very earnest in this thing, some are very eager in this thing, some are often telling about this thing about not doing some things in the way some of the ones related to them by blood connection are doing such things . . . (¶ 2874)
In the first two sentences “Naturally some knew” is modified to “Naturally some were certain,” a variance that points to the difference between the act of knowing something and the more general state of being certain that what is known is true. Again, in the fourth and the fifth sentences the same phrases are repeated and slightly modified to generalize the third sentence. So, in the fourth sentence, “some” and “some of them” are incorporated to make the third sentence more general. In the fifth sentence, all parts of the sentence are modified to be more general. “He” becomes “some,” and the past-tense “did” (which signifies that something happened) becomes “do not like to do,” which signifies that, in general, something might happen; the supposition that this thing is not liked further implies that it might not happen. The sixth sentence repeats within itself and continues to generalize the third sentence by becoming a discussion about how others feel (“very earnest” and “very eager”) about what David does. The repetitions in this brief example are complex, and similarly complex patterns of repetition-with-variation pervade the text. Providing appropriate interfaces for people to study repetition has been our goal in these projects, based on the conviction that although Stein is a special instance of this approach to writing, she is not alone in her use of repetition-with-variation.
Discovering involves preliminary actions like seeking for repetitions and detecting them, either of which can be accomplished manually or in an automated process (Unsworth, 2000).
Comparing is another primitive, related to analyzing the information collected. After patterns have been discovered, they can be compared with one another. Our prototypes all support this feature, although it takes different forms in each design (Unsworth, 2000).
Deconstructing is one of the primitives listed by Uszkalo and Ruecker (2007). Deconstructing is more than just disassembling. It is taking something apart to show how it contains internal inconsistencies or fault lines. In visualizing patterns of repetition, a text is disassembled into n-grams (see “Text mining for repetition,” below), and this disassembly is part of the deconstructive process of exposing the constructed nature of what may otherwise have seemed natural or essential.
Contextualizing places discovered material back into a larger framework for interpretation (Uszkalo and Ruecker, 2007). The context typically consists of the original location in the larger sequence of the text, but may also include visualizations that provide an overview of some kind.
Observing repetition in literary prose comes naturally during the normal process of reading. Most undergraduate readers of Tess of the D’Urbervilles, for instance, become aware of the symbolic role of certain characters as playing cards in the novel, and readers of The Great Gatsby begin to recognize over time that watching eyes recur as a theme, symbolized in part by the giant pair of eyeglasses staring over the landscape from the optometrist’s advertising billboard. By spotting such repetition, readers are able to make one kind of interpretive sense of the material in front of them. Whether identifying such repetition is significant to a particular researcher is an issue that needs to be addressed in each case. Spotting instances of repetition is going to be more useful for some kinds of research tasks than others, but in general, part of the work of humanities scholars is to identify patterns and discuss them from different perspectives. Since repetition is one form of pattern, its presence in a text can inspire further investigation, for example into higher-level interpretations of the text. Repetition in this sense can be considered a kind of metatext that suggests to the reader that here is something worth paying closer attention to; the author, at least, felt that this material was important enough to be worth repeating. In some cases, the repetition can be blatant, involving exact or near-exact reuse of the same words or phrases. Other repeated elements worth noting by a reader can occur at more subtle levels, including themes or motifs, symbolic elements, and extended metaphors. This higher-order repetition might be signaled by the lower-order repetition of significant words and phrases at the lexical or syntactic levels, or it might appear at the semantic or even at the highest, pragmatic levels, where the larger intentions of the text come into play.
Repetition strikes many readers as a slightly jarring experience, temporarily reminding them that they are in the middle of the reading process and implying, not necessarily that something unusual is going on with this narrative, but that they should entertain the possibility that something significant might be indicated. A question that naturally arises is how much repetition is necessary for the reader to begin to take notice of it. Human perception is highly nuanced. Logically, a single instance of anything is unremarkable, two occurrences are noteworthy but may be the result of accident, inattention, or coincidence, but three is a magic number that indicates something significant is happening.
A system designed to illuminate patterns of repetition is not a universal reading machine, but rather a tool for scholars to use in carrying out a specific set of related tasks, involving diving in and out of texts to look at different levels of information with the eventual goal of producing an understanding of material that would otherwise be difficult to manage. In most cases, a reader can spot repetition in a single document simply by reading. Exceptions could arguably include books that are rich in repetition, where the density of repetition has a kind of numbing effect on the mind. Examples of this kind of experimental writing include The Making of Americans, as well as some of the poems or novels of the German expressionists (e.g. Georg Heym’s Gedichte or Albert Ehrenstein’s Tubutsch). However, not every literary-critical task involves reading a single document. As increasingly more literary source materials have become available online, the opportunity has arisen to take a step back and look through reams of prose using algorithmic systems of various kinds to identify patterns that a reader might naturally spot within a single novel, but which would prove far more difficult to see across dozens or hundreds of novels.
From the analytical perspective, choosing which items should be counted as repetitive is a task that requires consideration of factors such as the psychology of writing and reading, as well as what is possible technically. If we choose the “n-gram” as the typical unit to search for, the first two choices that need to be made are:
What exactly is meant by “gram”?
What is the value of “n”?
In increasing order of abstraction, the grams might be words, lemmas, or parts of speech. For example, setting the grams as words would mean the phrase “fallen leaves on the ground” would be noted by the system if it was exactly repeated in more than three different places. However, “fallen leaf on the ground” would be a different n-gram and not counted as a match. Choosing lemmas for grams, on the other hand, would mean the words would be stripped of morphology before being listed as patterns for comparison. With lemmatized grams, the system would recognize all of the following phrases as repetitions: “fallen leaves on the ground,” “falling leaf on the grounds,” “fallen leaves on the grinding,” and so on. Patterns based on parts of speech would be even more forgiving, and therefore even more common. Examples might include “adjective adjective noun” or “verb noun infinitive,” where the former would match phrases like “big red dog” with “fuzzy woolen sweater” while the latter would match “told him to go” with “bought horses to sell.” For the choice of the size of “n,” one approach is to make the number as small as is reasonable, which is to say three words long, since repetitions of single words or pairs of words would produce a very large number of uninteresting hits. For some collections and some texts, even an “n” of 3 is going to result in a great many instances of repetition. The list can quickly become overwhelming, unless the system also provides a number of tools for aggregating or summarizing the display. An alternative is therefore to have the system prepare a list of all repeated n-grams, starting with the longest “n” in the document set and working progressively smaller. Depending on the nature of the documents, this list can also become long.
What none of these strategies provides is a means of identifying cases of repetition that vary in the order of the words, or in cases where a single word is different or a word has been interposed. For example, “running around town” wouldn’t match “running all over town” or “[they were] in town, running around,” although semantically they are close enough that a human reader would consider identifying them as repetition. In order to be able to match patterns like “trouble is brewing” with “trouble was brewing,” the system would need to be able to specify mixed kinds of grams, so the pattern might be “trouble [verb] brewing,” or even “trouble [verb] lemma:brew.”
An interface that is designed to help a reader to study repetition in a document or set of documents should provide a number of features. It must automatically generate lists of n-grams. Ideally, the user should be able to specify what the value of “n” is and what “gram” means. The system should include a reading view that lets the user see the n-grams in the context of the document. The reading view should provide this context either within the entire document or else extract the sentences or paragraphs with n-grams in them and assemble these excerpts into a reading list. To keep the task focused, the user should be able to search for particular words or phrases of interest that may occur as repetition. To make browsing possible, the user should also have access to the complete set of repeated phrases. Some of these larger lists or sets may necessitate visualization methods that attempt to accommodate many items in a single display. Perhaps most importantly, there need to be tools for manipulating the results, so that different kinds of patterns can be brought out and examined.
For the purpose of examining overviews of Stein’s work, Tanya Clement has worked with Anthony Don, Catherine Plaisant, and other researchers in the Human-Computer Interaction Lab at the University of Maryland (HCIL) to create FeatureLens (Figure 1). The FeatureLens interface allows the user to study a text using four distinct views:
Frequent patterns: a list on the left of repeated phrases that use the search term entered by the user;
Sections overview: a central panel showing the phrases colour-coded in the context of the document;
Collection overview: a line graph at the top displaying frequencies; and
Document overview: a reading view to the right.
The user also has the ability to choose trends of repetition across the document, using the buttons placed above the list (top left). One of these buttons identifies, for example, trends where repetition is common at the beginning and end of the document, but drops off in frequency in the middle. Eight such trend selections are available in the version shown here. The interface also uses scrollbar confetti (far right) to mark locations in the larger document.
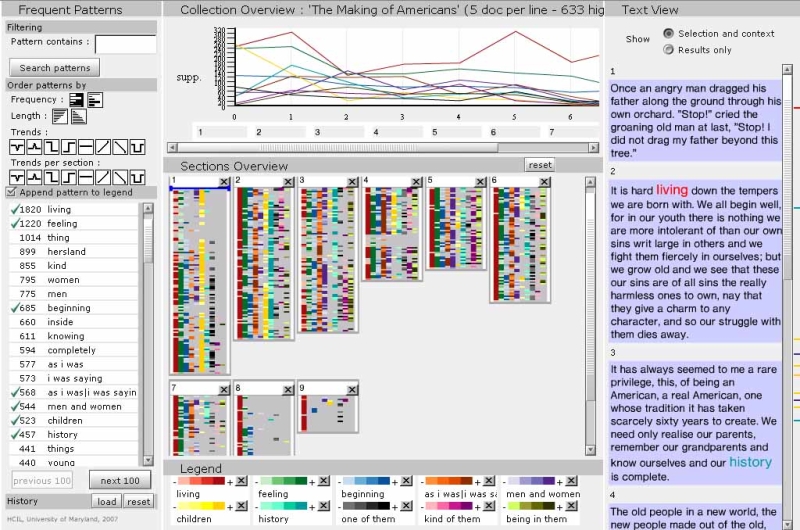
Figure 1: FeatureLens was developed by Anthony Don during his postdoctoral research fellowship with Catherine Plaisant at the Human-Computer Interaction Lab (HCIL) in Maryland. This screen shot shows Tanya Clement working on Gertrude Stein’s The Making of Americans. (http://www.cs.umd.edu/hcil/textvis/featurelens/).
In our designs, introduced here, we have been taking three distinct approaches to the same interface and visualization challenges. Our first project, called “dialR,” assumes as its constraints a contemporary PC environment, with a regulation monitor and interface options. The browsing tools consist of a series of radar screens, where the user can watch the system scanning through a document while it highlights the results in a set of transparent sheets that provide the document overview. Our second project, “Repetition graph,” began with the strategy of removing the conventions of the codex page and starting over again with the rudimentary building blocks of text—words in sequence. Plotting the words on a graph or setting them as a string in space produces useful results in the form of a visual thumbprint of the repetition in a text. Our third project, “Wall of text,” is predicated on the availability of high-resolution wall-sized displays, which we somewhat perversely envision as accommodating, in a single view, the study of repetition within a single novel. The display consists of a series of microtext columns, each one of which contains the entire text of the novel. The columns are multiplied according to the number of repetitions of a repeated text and are aligned in relation to a reading slot in the middle.
In this project, we designed a document interface that allows readers to select a variety of features, presupposing an ability to identify automatically appropriate n-grams (Figure 2). The user experience here is intended to be one of working not with a sequential process, but rather in a kind of “text visualization lab,” where the text appears as a volume of space and the goal is experimentation.
Figure 2: The dialR interface has a series of radar screens across the bottom and a set of transparent sheets in the main area. The user provides a word or phrase and the system scans for passages that include that word or phrase, highlighting results in the transparent sheets. A reading view is available on the right and can be configured to contain either continuous prose or excerpted sections. (http://www.pix.com.ar/UofA/DialR.html).
The dialR interface has a series of radar screens across the bottom and a set of transparent sheets in the main area. The user provides a word or phrase and the system scans for passages that include that word or phrase, highlighting results in the transparent sheets. A reading view is available on the right and can be configured to contain either continuous prose or excerpted sections. (http://www.pix.com.ar/UofA/DialR.html).
The dialR browsing tools consist of a series of radar screens where the user can set up a query on a word or phrase and watch the system scanning through a document. If we consider the text as a string of words (see “Repetition Graph,” below), the radar might be seen as a coil made by rolling up the string. Positions marked on the face of the coil therefore correspond to the position of the repeated phrase in the sequence of the text. Results of the scan are highlighted in a set of transparent sheets that sit angled to the viewer to provide the document overview. The sheets are like large pages of microtext, with the text laid out in a manner similar to how it would be formatted in a regular book, with colours applied to the repeated phrases to mark their location. Since the sheets are large and the text is small, the lines would be too long for convenient reading in a conventional sense, but the context is still available. The radar screens are used as a metaphor to reinforce the idea of seeking and detecting a signal. In this case, signals contain matching words or combinations of words. A text can be a sequenced line of data or string of words, with a start and an end point. A text also can be approached as a “volume” of data. The semi-transparent layers in dialR are representations in space of a volume of text, allowing the user to view the findings in a contextual manner. The timeline on the bottom is a sequential history tool, similar in function to a history palette or undo command.
It is important to note that, like our other two projects, the dialR interface is a model in progress, based on collaborative, interdisciplinary work that proceeds in an iterative cycle. It is a design experiment, the goal of which is to provide a platform for experimentation by literary scholars.
This approach to text visualization began with the strategy of removing the conventions of the codex page and starting over again with the rudimentary building blocks of text: words and sequences of words. In considering new interface designs for dealing with electronic text, a perennial difficulty is the prevalence of the metaphor of the page (Stoicheff and Taylor, 2004). Although the codex page may be a good design solution for the printed book, it is not necessarily an optimum solution for digital text. In order to consider genuine visual alternatives, it is useful to strip away as many page conventions as possible and start from scratch in the new medium. By starting with a radically reduced representation of the document, we have opportunity to consider configurations of text that can be developed through two-dimensional and three-dimensional manipulations of the text string.
This project is inspired in part by the “Object Manipulation Model” conceived and described by John Bradley (2005). His approach, related to the concept of scholarly primitives, is to provide researchers with tools to support existing research processes at their various stages. He takes a look into “little things” scholars do in their everyday practice and asks whether it is possible to devise ways that computers can “augment” people’s performance by taking advantage of the flexibility of digital text. Bradley uses the process of annotation as an example. Computer-assisted annotation involves the mental organization of information in notes by directly mapping the relationships between the notes and the primary text into a visual structure — a diagram. The proposed form of the diagram is very flexible, permitting a wide range of interaction and allowing the user to arrange elements of the structure in a freehand way.
Our project also draws on the “Direct Manipulation Paradigm” of interface design described by Shneiderman (1997). This paradigm is based on three main premises:
Entities, operations/actions, relations, and results of interest to the user are represented in a continuous manner.
Meaningful physical actions are utilized (such as drag & drop or presses of buttons).
Results of appropriately rapid, gradual/incremental, and reversible actions are visible immediately.
Bradley’s object manipulation model and Shneiderman’s direct manipulation paradigm together suggest an approach that would allow the user to work with text strings in an intuitive manner by providing functions using dynamic, simultaneous, multithreaded viewing and re-configuring of text.
Our set of interface concepts begins with separated words as the discrete objects of manipulation and conceives various possibilities of mapping each word’s relations to other words in a visual manner. In this case, the relations/features we are especially interested in are repetitions of words in text and their frequency of occurrence. The relations we would like to depict are therefore the number of all repeated words in comparison to the whole vocabulary of the novel, as well as the frequency of occurrence of a chosen word, phrase, or fuzzy phrase related to an established unit of measurement.
A third conceptual thread in this work that remains to be addressed is the diagrammatic approach to typography. This approach is based on a special treatment of typographic features which in themselves play an active role in communicating the meaning of a text. Readers commonly recognize correspondences between typographic elements (including spatial arrangement) and informational content. The diagrammatic approach to typographic features can therefore have important implications for text visualization. It offers the possibility of mapping the results of analysis directly onto the appearance of a text through variations in its typographic features, enabling researchers to visualize the results of text analysis in a direct, intuitive manner, without mediation or translation into other abstract graphical forms. With this approach, the word “results” may even be misleading, since here the operation of text analysis directly influences the form of the text, rather than generating some new resulting object such as statistical data or a new visualization.
To summarize the preceding discussion: there are three main concepts that together strongly influenced our proposed visualizations — the direct manipulation paradigm, used in a context of an object manipulation model of interface, with visual aspects formed according to the principles of diagrammatic typography.
Repetition graph is an attempt to show all repetitions of all words in an entire text (Figures 3 and 4 show only part of the text as an example). Each unique word is assigned its own column, in sequential order of first occurrence in the text. Subsequent occurrences of a word are placed in the appropriate column (under the same word already used), and the text resumes on this new line at the horizontal point where the text was interrupted, unless the next word is also a repeated word, in which case it occurs one line lower in its relative column, and so on until a new word is introduced. In this way, the Y-axis consists of all repetitions in the entire text (the line is a unit: one line = one repetition), and the X-axis plots the entrance of each new word into the text. The X-axis therefore shows the full vocabulary of the novel.
The curve of the horizontal line is therefore a function of the concentration of repetition in a text: the more repetitions, the sharper the curve. Using this kind of chart, it is possible to visually compare two chapters, novels or other documents in terms of their overall use of repetition. As an aside, it is even possible to imagine an Oulipo-style novel written according to a graph drawn beforehand, according to a kind of visual plan of the novel. So, for example, a writer could decide that chapters 3-4 will contain only words which have already occurred in chapters 1-2. On the graph, chapters 3-4 would then appear as though the horizontal movement were abruptly cut off on the right.

Figure 3: The repetition graph, zoomed out. The words form a line graph showing occurrence of repetition. A stronger bend in the curve indicates more repetitions.

Figure 4: The repetition graph, zoomed in. One can see separate words in columns and rows according to their repetition in the text.
Another interesting interface direction builds on the recognition that for prose, at least, the “line starts” on the left side of the conventional text block are in many respects arbitrary, since the length of the line is established by convenience of printing and reading, rather than by some inherent properties of the text. In poetry, of course, the situation is different, where line starts are typically determined by the author. One means of adding significance to the configuration of line starts in prose is to allow the reader to choose a term, phrase, or fuzzy phrase to serve as the line start. The reader is then able to see the frequency of occurrence of the term or phrase throughout the entire body of the text (Figure 5).
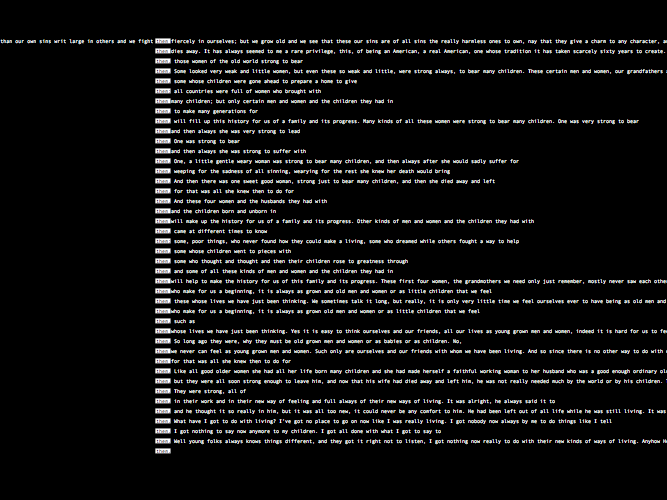
Figure 5: In this example, whenever the word “them” occurs, it is placed on the left end of the new line, below the previous occurrence of the word. The parts of the text in between the subsequent instances of the word form the chart bars: if the bar is longer it means the word occurs less frequently. The pattern of repetitions is clearly visible when the text is zoomed out. The unit, which enables comparison between bars, is the space of each character: since the design uses a mono-spaced typeface, every character occupies the same amount of space. The main advantage of this approach is that the way the text is formatted shows a characteristic feature of the text (in this case the distance between each repetition of the word “them”).
While the first two designs are based on an X-Y Cartesian grid, it is also possible to add a third dimension. Figure 6 shows two angles of a 3D version (paper prototype) of Figure 5, where we have connected the ends of each chart bar (line of text) to form a loop and then connected each loop with the one below it at the point of the repeated word, so that the repetition of the word “them” forms a spine where the loops meet. Thus it is possible to read the text going around the model from top to bottom. The loops formed by the lines of text should be circles, whose diameters indicate the distance between each repetition of the word. The advantage of this model as compared to 2D charts is that it is easier to get an overview of the text surrounding the chosen word, and the distance between occurrences is still easily compared (by juxtaposition of ring diameters) when the model is seen from the top or bottom.

Figure 6: By connecting the ends of the lines in Figure 5, we create a 3D version of the repetition graph, with the repeated word or phrase running down the spine and the length of text between repetitions indicated by the size of the loops.
Further designs based on the “loops of text” are currently being developed, including the possibility of using the loops as ways of representing different kinds of information (Figure 7). The user might choose, for instance, to have loops to the left of the spine indicate passive voice, while loops to the right would be for active voice. The loops would cross indicating the change of the voice in the text.

Figure 7: Multiple loops can be used to show different kinds of information, as selected by the user. The loops on one side, for instance, could consist of reported dialogue, while the other is for narrative prose.
Our third design makes use of the affordances of large-format displays. In the last ten years, the use of large-format displays for the purpose of information dissemination, entertainment, or persuasion has increased in popularity (Signindustry.com, 2007). Commercial advertising (e.g. Times Square), one form of a persuasive display, is the most common (Dietz et al., 2004). In size and placement, large-format persuasive displays mimic traditional billboard advertisements; in content and multimedia use, they mimic television. Large-format displays are also used in a variety of ways in sports stadiums and even mega churches. In sport stadiums they display live action details, announcements, and shots of the viewing public. In mega churches they are used to support religious practice in ways similar to those used in the classroom: to display words to hymns and Bible verses, illustrate sermons, share announcements and video, and clarify material through PowerPoint slides (Wyche et al., 2007). These instances of large-format display are passive in nature and, for the most part, rely on viewing from a distance.
Large-format interactive displays have been used in a number of disciplines, for purposes including intelligence analysis (Booker et al., 2007), enhancing collaboration (Ni et al., 2006), and enriching informal shared spaces, such as universities, conferences, and cafés (Izadi et al., 2005), as well as physical library spaces (Grønbæk et al., 2006). Immersive imagery displays developed by Dietz and colleagues each contain an array of sensors that measure viewer proximity to parts of the screen and react accordingly, allowing for several simultaneous interactions (Dietz et al, 2004).
In addition to large-format displays, work has also been done on providing data on other interior surfaces. InfoGallery was developed and implemented as a Web-based infrastructure for enriching the physical library space with informative exhibits of digital library material and other relevant information such as RSS feeds (Grønbæk et al, 2006). Information is presented on a variety of surfaces in the library, including large-format cylindrical displays, ceilings, large flat panels, and floors. Some of the library displays enable interaction. For example, visitors can click or tap on a touch-sensitive surface to explore a piece of information in depth. Visitors can also drag a reference to this information to a Bluetooth phone or send it to an email address.
On the usability of large-format displays, Ni et al. (2006) studied the effects of display size and resolution on task performance in an information-rich virtual environment (IRVE). They found that users were most effective at performing IRVE search and comparison tasks on large-format, high-resolution displays. In addition, users working with large-format displays became less reliant on wayfinding aids in the IRVE to develop knowledge of the space they were navigating.
If one of the goals of text visualization is to represent meaningful features in the context of the entire document, one of the difficulties that immediately arises is a limited display space that forces the sequential privileging of these features. In representations that require scrolling, for instance, only the first few instances of the identified features are visible. One solution to this difficulty is to provide a microtext representation that fits into a single viewing field, but allow the user to navigate by zooming in toward the text in order to make it readable (Small, 1996). Another strategy is to provide simultaneous document representations at different levels of granularity (Ruecker et al., 2005) so that the user can easily switch between an overview, a reading view, and specialized views that emphasize various kinds of information (such as word frequencies, collocations, or parts of speech) (Sinclair, 2003).
In this project, we propose a wall-sized interface design that extends the notion of simultaneous document representation by providing the user with a set of complete microtext overviews of the document, one for every instance of repetition (Figure 8). This innovative design has three advantages for literary-pattern analysis that are not available in our other interface designs. First, the vast amount of available screen space eliminates concerns that would normally be introduced immediately about how much text can reasonably be shown and manipulated at one time. Second, the combination of the microtext columns and the reading slot means that the reader is working across multiple contexts that are each ready-to-hand and unambiguous in their relations. Third, a mechanism for selecting and displaying a pattern of repetitions, at random, provides an element of play and serendipity (Rockwell, 2003).
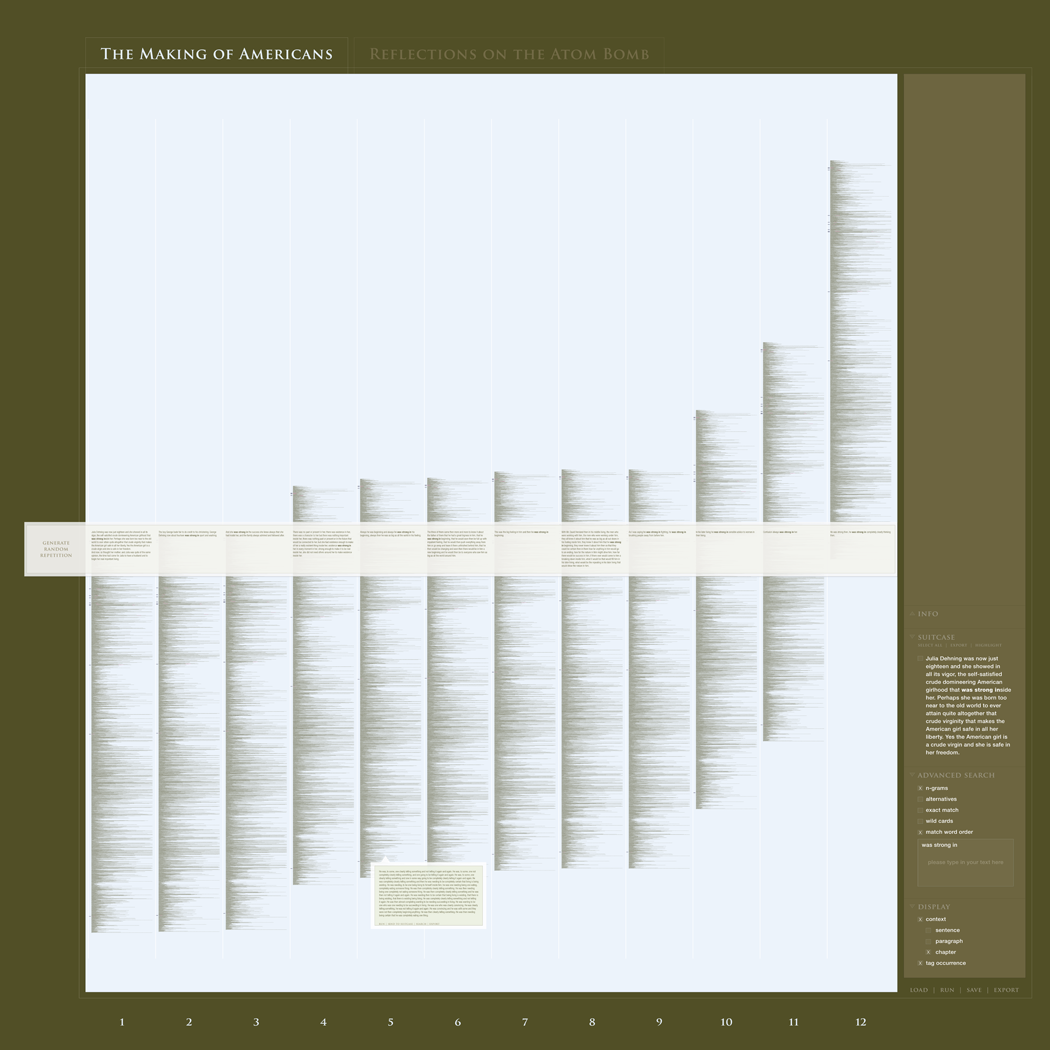
Figure 8: The wall-sized display allows the system to present a full copy of the novel for each repetition. Although the columns are microtext, they are aligned along a reading slot that magnifies the repeated phrase and its immediate context.
The screen is divided into the following parts:
The display panel for viewing the entire novel in microtext together with all specified repetitions
A right-hand control bar where the user can enter words or phrases to search for repeated forms, store results, and carry out other tasks
A reading slot running horizontally across the middle of the screen which displays the paragraphs containing instances of the repeated word or phrase
Tabs across the top to allow switching between different texts
Upon launching the interface, users access the document for analysis (in this case The Making of Americans) by clicking on the “load” button and selecting the desired document. Once the entire text of the novel has been loaded into the first column, users cannot read it, because it is a microtext. What they can read is the text in the reading slot, which appears in a legible font size.
When users are ready, they can identify or search for a repetition in a number of different ways:
The first way is just like a slot machine: they push the “generate random repetition” button. This is a discovery tool: try one, see if you like it, and if not, then push the button again and see what you get.
The second way is by highlighting a piece of text that is of interest, which will cause a menu to slide up from the bottom of the slot giving the user four options:
Run a default search
Send the highlighted text and its context to a temporary storage area, or “suitcase”
Send just the highlighted text to “advanced search” for further customization
Export that chunk into, for example, a .txt file
The third way is to enter a search string, which will cause the system to identify all repetitions that contain that string.
To minimize walking back and forth between the text and the menu, the user can un-dock the menu and drag it closer to the text. Once a user runs a repetition search, the system generates one complete copy of the novel for every instance of the repetition. In the sketch shown in Figure 8, the system found 12 repetitions, which were loaded into 12 columns, each one a full copy of the novel with a superimposed “reading slot” that contains the repeated word or phrase in its paragraph context. Each column is separated with a thick, white line; and each is numbered on the bottom. For every instance of the repetition, the system marks the spot of the repetition by making a tick on the left side, in the gutter. The user can also roll over any line of text that is not behind the slot, and see a customizable reading-view.
This interface will only be technically viable with the availability of low-cost high resolution wall-sized displays. Such displays have been the subject of experimentation by commercial developers of electronic paper (e.g. Xerox, E-Ink, Phillips) and by theorists working with alternative forms of reading, such as the prototype reading wall, where users interact with a wall of text by physically sliding panels containing hyperlinks into position for more information (Back et al., 2001).
The interfaces discussed here are currently still at the design stage, which means they are in the process of iterative development before they will be implemented as prototypes. The dialR design is the furthest along the curve, since it already exists as an online Flash movie (http://www.pix.com.ar/UofA/DialR.html). User studies of these designs will help us to determine additional functionality that may be possible and useful and to identify existing areas still in need of improvement. We have a protocol that we’ve been developing for studying interfaces prior to prototyping them which includes asking people a series of questions about how much they feel they would want to use a particular affordance designed in a specified way (Ruecker, 2006). Our user studies are intended to address the following issues:
What affordances, if any, emerge from the use of the different interfaces?
What techniques can be used to prevent information overload?
Which functions do humanities scholars perceive in the various interfaces as being of potential benefit in conducting their research?
How do users interact with the various interfaces?
The authors wish to acknowledge the support of the Andrew W. Mellon Foundation, the Social Sciences and Humanities Research Council of Canada, and the Natural Sciences and Engineering Council of Canada. Our interface designs have been informed by the work of our colleagues on the MONK project, which has as principle investigators John Unsworth at University of Illinois at Urbana-Champaign (UIUC) and Martin Mueller at Northwestern University. The kind of back-end processing discussed here is available from the SEASR system at the National Center for Supercomputing Applications (NCSA) at UIUC. Our main contact with NCSA is Loretta Auvil. Our primary interlocutor from the user community has been Tanya Clement, with input also coming from Martin Mueller. Our interface design colleagues at the University of Maryland, in particular Anthony Don and Catherine Plaisant, have been addressing this topic from their own perspective, with spectacular early results in the form of the FeatureLens. It is great to have the chance to work with all of these people.
BACK, M., R. GOLD, A. BALSAMO, M. CHOW, M. G. GORBET, S. R. HARRISON, D. MacDONALD, and S. L. MINNEMAN. (2001). “Designing Innovative Reading Experiences for a Museum Exhibition”, IEEE Computer 34.1: 80-87.
BOOKER, John, Timothy BUENNEMEYER, Andrew SABRI, and Chris NORTH. (2007). “High-Resolution Displays Enhancing Geo-Temporal Data Visualizations”, in Proceedings of the 45th Annual Southeast Regional Conference, Winston-Salem, NC, March 23-24, 2007. New York: ACM Press: 443-448.
BRADLEY, John. (2005). “What You (Fore)see is What You Get: Thinking About Usage Paradigms for Computer Assisted Text Analysis”, Text Technology 2: 1-20.
BRILL, Louis M. (2007). “LED Billboards: Outdoor Advertising in the Video Age”, Signindustry.com: the Online Magazine for the Sign Industry, (URL http://www.signindustry.com/led/articles/2002-07-30-LBledBillboards.php3).
CLEMENT, Tanya, Anthony DON, Catherine PLAISANT, Loretta AUVIL, Greg PAPE, and Vered GOREN. (2007). “Something that is Interesting is Interesting Them: Using Text Mining and Visualizations to Aid Interpreting Repetition in Gertrude Steins The Making Of Americans”, Digital Humanities 2007, University of Illinois, Urbana-Champaign, June 2007.
CLEMENT, Tanya. (2006). “What to do, What to do, What to do with 3182 Paragraphs: The NORA Project and Repetition in Gertrude Stein’s The Making of Americans”, paper presented at the Chicago Colloquium on Digital Humanities and Computer Science, University of Chicago, November 2006.
DIETZ, Paul, Ramesh RASKAR, Shane BOOTH, Jeroen van BAAR, Kent WITTENBURG, and Briam KNEP. (2004). “Multi-Projectors and Implicit Interaction in Persuasive Public Displays”, in Proceedings of the Working Conference on Advanced Visual Interfaces, Gallipoli, Italy, May 25-28, 2004. New York: ACM Press: 209-217.
FIORENTINO, Carlos, Stan RUECKER, Piotr MICHURA, Milena RADZIKOWSKA. (2007). “Dial R for Repetition”, paper presented at the Society for Digital Humanities (SDH/SEMI) conference, University of Saskatchewan, Saskatoon SK, May 2007.
GRØNBÆK, Kaj, Anne ROHDE, BalaSuthas SUNDARARAJAH, and Sidsel BECH-PETERSEN. (2006). “InfoGallery: Informative Art Services for Physical Library Spaces” in Proceedings of the 6th ACM/IEEE-CS Joint Conference on Digital Libraries, Chapel Hill, NC, June 11 - 15, 2006. New York: ACM Press: 21-30.
IZADI, Shahram, Geraldine FITZPATRICK, Tom RODDEN, Harry BRIGNULL, Yvonne ROGERS, and Siân LINDLEY. (2005). “The Iterative Design and Study of a Large Display for Shared and Sociable Spaces”, in Proceedings of the 2005 Conference on Designing For User Experience, San Francisco, CA, November 03-05, 2005. ACM International Conference Proceeding Series, vol. 135. New York: ACM Press: 2-19.
MICHURA, Piotr, Stan RUECKER, Carlos FIORENTINO, and Melina RADZIKOWSKA. (2007). “A Text is a String of Words”, paper presented at the Society for Digital Humanities (SDH/SEMI) conference, University of Saskatchewan, Saskatoon SK, May 2007.
NI, Tao, Doug A. BOWMAN, and Jian CHEN. (2006). “Increased Display Size and Resolution Improve Task Performance in Information-Rich Virtual Environments”, in Proceedings of Graphics Interface 2006, Quebec, Canada, June 07-09, 2006. ACM International Conference Proceeding Series, vol. 137. New York: ACM Press: 139-146.
RADZIKOWSKA, Melina, Stan RUECKER, Carlos FIORENTINO, and Piotr MICHURA. (2007). “The Novel as Slot Machine”, paper presented at the Society for Digital Humanities (SDH/SEMI) conference, University of Saskatchewan, Saskatoon SK, May 2007.
ROCKWELL, Geoffrey. (2003). “Serious Play at Hand: Is Gaming Serious Research in the Humanities?” Text Technology, 2.
RUECKER, Stan. (2006). “Proposing an Affordance Strength Model to Study New Interface Tools”, paper presented at the Digital Humanities 2006 conference, at the Sorbonne, Paris, July 5-9, 2006.
RUECKER, Stan, Eric HOMICH, and Stéfan SINCLAIR. (2005). “Multi-Level Document Visualization”, Visible Language 39.1 (January/February): 33-41.
SHNEIDERMAN, Ben. (2001). “Inventing Discovery Tools: Combining Information Visualization with Data Mining”, Information Visualization 1.1 (2002): 5-12. Also appeared in Discovery Science 4th International Conference 2001 Proceedings.
SHNEIDERMAN, Ben. (1997). “Direct Manipulation for Comprehensible, Predictable, and Controllable User Interfaces”, Proceedings of 1997 International Conference on Intelligent User Interfaces, Orlando, FL, January 6-9, 1997, 33-39.
SINCLAIR, Stéfan. (2003). “Computer-Assisted Reading: Reconceiving Text Analysis”, Literary and Linguistic Computing 18.2: 175-184.
SMALL, D. (1996). “Navigating Large Bodies of Text”, IBM Systems Journal 35: 3-4.
STOICHEFF, Peter, and Andrew TAYLOR. (2004). The Future of the Page, Toronto: University of Toronto Press.
UNSWORTH, J. (2000). “Scholarly Primitives: What Methods do Humanities Researchers Have in Common, and How Might Our Tools Reflect This?”, paper presented at a symposium on Humanities Computing: Formal Methods, Experimental Practice sponsored by King’s College, London, May 13, 2000.
USZKALO, Kirsten, and Stan RUECKER. (2007). “Playing with Witchcraft: Digitizing, Structuring, and Visualizing Early Modern English Witchcraft Texts”, paper presented at the Rooms of Their Own: Women in the Knowledge Economy and Society conference, University of Alberta, Edmonton, May 2-4, 2007.