Old English Glossaries: Creating a Vernacular [1]
CHWP B.36, publ. November 1997. © Editors of CHWP 1997. [First published in CCH Working Papers, 4 (1994) and in Dictionnairique et lexicographie, 3 (1995).]
KEYWORDS
Old English, glossaries, Latin, bilingual dictionaries, information structure, vocabulary, logical order, alphabetical order, class glossary
The response of a reader in this post-modern age when confronting for the first time an Old English glossary is that of surprise. The strangeness and the novelty of what we survey arise from the disjunction between our expectations of what a glossary should be, and what, in fact, exists for this genre in the earliest period of English, between the seventh and the twelfth centuries. A glossary, as we all know, is 'a partial dictionary' (OED2 s.v. glossary1, main sense). We assume, almost without question, that it is an alphabetical word list pertaining to a particular subject matter (such as a glossary of medical terms) or to a specific piece of writing (such as a glossary to the books of the Bible). We also assume that its intent is illumination: to guide the reader from an unknown or opaque term (in either a foreign language or one's own) to a term which is familiar or, at least, comprehensible. As we explore the possibilities of creating Early Dictionary Databases, I wish to test our assumptions about dictionaries against the evidence of the Old English glossaries.
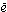 ag, gewrit, and
ymele, suggest either a piece of paper, or a document, or what is
written; one, scrad, from its context as a gloss to
Isidore 6.14.8, has the sense '(emended) part (of a text)'. There seems not
to be any word in Old English which conveys the notion of "slip". According
to the OED, the noun schedule in the sense of '[a] slip or
scroll of parchment or paper containing writing [...] a short note' is not
attested in English until 1397 (OED2 s.v. schedule, sense 1).
This is confirmed by the MED in its entries for ced
ag, gewrit, and
ymele, suggest either a piece of paper, or a document, or what is
written; one, scrad, from its context as a gloss to
Isidore 6.14.8, has the sense '(emended) part (of a text)'. There seems not
to be any word in Old English which conveys the notion of "slip". According
to the OED, the noun schedule in the sense of '[a] slip or
scroll of parchment or paper containing writing [...] a short note' is not
attested in English until 1397 (OED2 s.v. schedule, sense 1).
This is confirmed by the MED in its entries for ced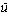 le and scedle. The noun slip
in the sense of '[a] piece of paper or parchment, esp. one which is narrow
in proportion to its length' is not attested in English until 1687
(OED2 s.v. slip sb.2, sense 10.a).
le and scedle. The noun slip
in the sense of '[a] piece of paper or parchment, esp. one which is narrow
in proportion to its length' is not attested in English until 1687
(OED2 s.v. slip sb.2, sense 10.a).
The Latin lemmas in Ælfric's Glossary are also of importance. R.L. Thomson noted in 1981 (Thomson 1981: 155) that Ælfric's Glossary displays a number of medieval Latin terms which have not been fully incorporated into the dictionaries. Ælfric's Latin contribution is on various levels: he provides further attestations of words which first appear in Britain between the sixth and tenth centuries; much-needed attestations for about twenty poorly-attested words; antedatings for a number of items in Latham's Revised Medieval Latin Word-List; and twenty-five new words not previously recorded, twelve of which are botanical.[8] Here is a wealth of material which, Thomson contends (158), was unlikely to contain words not in use in Ælfric's time if we presume his goal was to teach his students the basic vocabulary of Latin for their everyday monastic life. Thomson's point, although he does not state this explicitly, is that not all glossaries are the same. While we cannot attribute a record of normal usage to most glossaries, exceptions do occur, and one of them is Ælfric's Glossary. The evidence of the Latin vocabulary seems then to support the evidence of the English vocabulary: for this particular glossary, at least, we do not have a learned vocabulary but rather the vocabulary of ordinary life in the monastery. The number of versions extant, seven from the early medieval period (Cameron 1973: 86 [B.1.9.2]), tend to reinforce this conclusion.[9]
The importance of this class glossary in both the history of English and medieval Latin is without question, and we would certainly choose to include it in an Early Dictionary Database. What then are our resources for making it machine-readable? Unfortunately, the last published edition of the "only complete copy and probably the earliest" manuscript (Ker 1957: No. 362) of Ælfric's Glossary is Julius Zupitza's edition of 1880.[10] Marilyn Butler's edition of the early Middle English version of the Glossary exists only as an unpublished 1981 dissertation. Although there seems to be a growing interest in the problems of Anglo-Saxon glossography, as is demonstrated by the conference held in Brussels in 1986 devoted exclusively to this topic (Derolez 1992), there have been no new editions of Old English glossaries published in almost twenty years (Pheifer 1974, Stracke 1974). For the Electronic Corpus of the Dictionary of Old English we have had to input editions of glossaries which exist mainly as editions published in the last century or the first quarter of this century or as unpublished dissertations. This is not an ideal situation, but reflects the state of scholarship in this particular area of the discipline.
The Épinal Glossary not only differs from Ælfric's class glossary in form but also in content and purpose. Although it encompasses some ordinary vocabulary, it has a number of rare and restricted words which are difficult because they are seldom encountered in normal use. In its level of difficulty, Épinal is more typical of Old English glossarial material than is Ælfric's Glossary. It is timely, then, to recall here some of the various anxieties associated with these difficult glossaries within a manuscript culture:
The Épinal Glossary contains some 3200 entries; 970 entries, a little more than 30%, have Old English glosses.[12] The material is arranged in six columns, with the repeating pattern of a column of lemmas, a column of glosses. Unlike Ælfric's Glossary which is based on one source, Épinal draws on a number of sources: the Hermeneumata Glossary, Virgil scholia, the Hisperica Famina, the Vulgate, Gregory's Dialogues, Phocas' Ars Grammatica, the Abstrusa-Abolita glossaries, Aldhelm, Rufinus, Orosius, and, of course, Isidore, among others (Pheifer 1974: xliv-lvii). It is an impressive list and Épinal has been described as an "extract-glossary" (ibid.: liii) because its compiler obviously drew from one source and then another, and some of these sources would have been other glossary collections, known as glossæ collectæ (ibid.: liv).
What types of words did the glossator cull from his many sources? To test the range of the vocabulary in Épinal, I looked at all its Old English glosses, beginning with the letter A, a letter of average length in the Old English alphabet, with about 1500 headwords. Glosses in Épinal beginning with the letter A are filed under 37 different headwords in Fascicle A of the Dictionary of Old English. Even a limited look at the distribution of the material suggests much about the nature of the Épinal Glossary.
Nine words, 24% of the sample, are found only in Épinal and
other glossaries. Among these are the expected animal and plant names, such
as 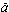 cweorna 'squirrel' (EpGl 776 aqueorna) and
alorholt 'alder copse' (EpGl 47 alterholt); and ailments of
various sorts, such as ampre1 'varicose vein' (EpGl 943
amprae) and angseta 'carbuncle, boil' (EpGl 633
angseta). Also to be expected is the technical vocabulary such as
lgeweorc 'material for producing fire, tinder' (EpGl
416 algiuueorc) and a verb depicting a handicraft, sowan 'to sew' (EpGl 660 asiuuid).
What was surprising, though, were the two verbs of appropriation and
violence restricted in use to the glossaries: gnettan 'to usurp' (EpGl 968 agnaettae), derived from
the noun gnett 'usury, interest' and r
cweorna 'squirrel' (EpGl 776 aqueorna) and
alorholt 'alder copse' (EpGl 47 alterholt); and ailments of
various sorts, such as ampre1 'varicose vein' (EpGl 943
amprae) and angseta 'carbuncle, boil' (EpGl 633
angseta). Also to be expected is the technical vocabulary such as
lgeweorc 'material for producing fire, tinder' (EpGl
416 algiuueorc) and a verb depicting a handicraft, sowan 'to sew' (EpGl 660 asiuuid).
What was surprising, though, were the two verbs of appropriation and
violence restricted in use to the glossaries: gnettan 'to usurp' (EpGl 968 agnaettae), derived from
the noun gnett 'usury, interest' and r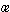 fsan 'to cut off, cut short, destroy' (EpGl
370 araepsid) -- no doubt both verbs reflect the tenor of their
sources. And, unfortunately, there was one puzzle we could not solve in
Épinal where the Latin lemma frixus 'roasted, fried'
is clear enough but we do not know where the Old English figen comes from, and it is possibly a corrupt form.
fsan 'to cut off, cut short, destroy' (EpGl
370 araepsid) -- no doubt both verbs reflect the tenor of their
sources. And, unfortunately, there was one puzzle we could not solve in
Épinal where the Latin lemma frixus 'roasted, fried'
is clear enough but we do not know where the Old English figen comes from, and it is possibly a corrupt form.
There are another ten words (26%) whose use is mainly restricted to
glossaries, glosses and poetry. Among these is the botanical term te 'oat; wild oat' (EpGl 460 atae); the technical
terms wel 'hook', glossing harpago 'hook,
talon' (EpGl 30 auuel uel clauuo), and m
which is perhaps a 'branding iron' (EpGl 183 haam); and the legal
term nweald 'absolute power' glossing
monarchia 'monarchy' (EpGl 483 anuuald).[13] Most interestingly, fully 40% of the vocabulary of
the letter A in the Épinal Glossary is part of the
general vocabulary of Old English, found in a range of texts and in the main
senses of well-attested words of ten or more occurrences. Among these are
the common animal and plant names, such as apa 'monkey or ape' (EpGl
692 apa); alor 'alder tree' (EpGl 36 alaer);
apuldor 'apple tree' (EpGl 497 apuldur); the adjective nhende 'one-handed' (EpGl 487 anhendi); and those
verbs of debilitation: seolcan 'to become sluggish,
indolent' (EpGl 391 asolcaen); slacian 'to
slacken, become weak' (EpGl 350 aslacudae); swindan 'to grow weak, waste away' (EpGl 914
asuundnan).[14] Yet it is the first group of
words I spoke of, those terms limited exclusively to the glossaries,
particularly the unsolved puzzles, which confer on Épinal the
reputation as a hard-word glossary.
Henry Sweet, that astute but often irascible lexicographer of Old English, once opined that the process of translation from Latin to Old English gave rise to "a certain number of words which are contrary to the genius of the language, some of them being positive monstrosities" (Sweet 1896: viii). He denigrated "these unnatural words" because they often created "unmeaning compounds" (ibid.: viii). While his charge may have some validity for those Old English words formed by translating the component elements of the Latin in a mindless and mechanical way (such as prædicere 'to predict' being rendered by OE beforan cweþan), it is certainly not true of the glossaries we have looked at in this analysis. The glossary produced by Ælfric is what we would expect from the most gifted prose stylist in the Old English period. It is an educational tool which keeps its audience firmly in mind, deploying language which is both clear and standard. My analysis of the Old English vocabulary beginning with the letter A in the Épinal Glossary suggests that even the most restricted vocabulary, those words limited in use to the glossaries themselves, show natural patterns of word-formation, for many of the compounds found there are shaped in an intelligent manner from native elements. We do not find in either glossary the "unnatural", "unmeaning" language so scorned by Henry Sweet.
I would like to conclude with a comment on methodology. I would have written this paper more laboriously and much more tentatively were it not for the Dictionary of Old English Corpus in Electronic Form. This database has allowed me to access at least one copy of each Old English text and whatever Latin was attached to it in a manuscript. My searches on the Latin were not limited to the glossaries themselves but also encompassed the interlinear glosses (such as the interlinear glosses to the Psalter) which comprise 24% of our corpus. I was able, therefore, to place the evidence concerning particular words in the glossaries against the evidence of the full corpus, both Old English and Latin, in order to make judgements about ordinary and learned vocabulary, frequent and rare occurrence, standard and non-standard use. Even more significantly, electronic searches have freed us from the logical order of the class glossaries and the alphabetical tyranny of most word lists. At the end of the twentieth century, we have reconfigured these medieval research tools into our own idiom so that they again speak -- this time to us -- with the authority and presence which they possessed a thousand years ago.
[1] I wish to thank Ian and David McDougall for help on particular points but
especially for bringing Lloyd W. Daly's monograph and Tom McArthur's book
to my attention. I wish also to thank the Social Sciences and Humanities
Research Council of Canada and the National Endowment for the Humanities for
their support of the research of the Dictionary of Old English project.
[2] These figures are derived from the Directory of the Electronic Corpus.
Later figures in this paper are drawn from the Electronic Corpus itself.
[3] Ker 1957: No. 317 is followed in the assignment of dates.
[4] Ker 1957: No. 317 states that "[t]he orthography of the English glosses is
throughout extremely confused".
[5] In the fragment extant today, only the sequence n-o-p-q is found
(Franzen 1991: 196-7, App. 1, MS G).
[6] For a different perspective, see McArthur (McArthur 1986: 77) who suggests it is
the printing press which led to the dominance of alphabetical order.
[7] Butler (Butler 1981: 22) also treats the glosses to Latin testudo and
cypressus but with different emphasis.
[8] This information is extracted from Thomson's list of vocabulary items,
pp. 156-60.
[9] Butler (Butler 1981: 19) notes that the two sets of later medieval excerpts and five
transcripts from the sixteenth and seventeenth centuries posit the existence
of four other eleventh-century manuscripts otherwise unknown.
[10] A new edition of this text is in preparation by Ronald Buckalew for the
Early English Text Society, but publication is not expected for several
years.
[11] Six of the letters, D, E, H, X, Y,
Z, do not have this second sequence in AB-order; noticed by Pheifer
(xlii).
[12] Pheifer 1974: xxi; the precise figure for the Old English material was drawn
from the Directory to the Electronic Corpus.
[13] The other words inthis category are: dwinan,
ferian, gnidan,
ambiht, anm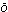 d, styntan.
d, styntan.